توزیع دوجمله ای توزیع های گسسته در EXCEL. توزیع دو جمله ای یک متغیر تصادفی توزیع دو جمله ای اکسل
بیایید توزیع Binomial را در نظر بگیریم، انتظارات ریاضی، واریانس و حالت آن را محاسبه کنیم. با استفاده از تابع MS EXCEL (BINOM.DIST)، نمودارهایی از تابع توزیع و چگالی احتمال می سازیم. اجازه دهید پارامتر توزیع p، انتظارات ریاضی توزیع و انحراف استاندارد را تخمین بزنیم. بیایید توزیع برنولی را نیز در نظر بگیریم.
تعریف. اجازه دهید آنها برگزار شود nآزمایشاتی، که در هر یک از آنها فقط 2 رویداد می تواند رخ دهد: رویداد "موفقیت" با احتمال ص یا یک رویداد "شکست" با احتمال q =1-p (به اصطلاح طرح برنولی،برنولیآزمایشات).
احتمال دریافت دقیقا x موفقیت در اینها n تست ها برابر است با:
تعداد موفقیت در نمونه x یک متغیر تصادفی است که دارد توزیع دو جمله ای(انگلیسی) دو جمله ایتوزیع) صو n – پارامترهای این توزیع هستند.
لطفا به خاطر داشته باشید که استفاده کنید طرح های برنولیو بر این اساس توزیع دو جمله ای،شرایط زیر باید رعایت شود:
- هر آزمون باید دقیقاً دو نتیجه داشته باشد که معمولاً "موفقیت" و "شکست" نامیده می شود.
- نتیجه هر آزمون نباید به نتایج آزمون های قبلی (استقلال آزمون) بستگی داشته باشد.
- احتمال موفقیت ص برای تمام تست ها باید ثابت باشد.
توزیع دو جمله ای در MS EXCEL
در MS EXCEL، از نسخه 2010، برای یک تابع BINOM.DIST()، وجود دارد نام انگلیسی- BINOM.DIST()، که به شما امکان می دهد تا احتمال اینکه نمونه دقیقاً حاوی خواهد بود را محاسبه کنید X"موفقیت" (یعنی تابع چگالی احتمال p(x)، فرمول بالا را ببینید)، and تابع توزیع تجمعی(احتمالی که نمونه خواهد داشت xیا کمتر "موفقیت"، از جمله 0).
قبل از MS EXCEL 2010، EXCEL یک تابع (BINOMDIST) داشت که به شما امکان محاسبه را نیز می دهد. تابع توزیعو چگالی احتمال p(x).
BINOMIST () در MS EXCEL 2010 برای سازگاری باقی مانده است. فایل مثال حاوی نمودارها استو .

توزیع چگالی احتمالتوزیع دو جمله ای تعیین را دارد (n ; ص) .
بتوجه داشته باشید : برای ساخت و سازتابع توزیع تجمعی نمودار نوع کاملبرنامه ریزی کنید ، برای – چگالی توزیعهیستوگرام با گروه بندی
ب: برای سهولت در نوشتن فرمول ها، نام پارامترها در فایل مثال ایجاد شده است توزیع دو جمله ای: n و p.

فایل مثال، محاسبات احتمالات مختلف را با استفاده از توابع MS EXCEL نشان می دهد:

همانطور که در تصویر بالا مشاهده می کنید، فرض بر این است که:
- جامعه نامتناهی که نمونه از آن گرفته شده است شامل 10٪ (یا 0.1) عناصر معتبر (پارامتر) است. ص، آرگومان تابع سوم = BINOM.DIST())
- برای محاسبه این احتمال که در یک نمونه 10 عنصری (پارامتر n، آرگومان دوم تابع) دقیقاً 5 عنصر معتبر وجود خواهد داشت (آگومان اول)، باید فرمول را بنویسید: =BINOM.DIST(5، 10، 0.1، FALSE)
- آخرین، چهارمین عنصر تنظیم شده = FALSE، i.e. مقدار تابع برگردانده می شود ، برای .
اگر مقدار آرگومان چهارم = TRUE، تابع BINOM.DIST() مقدار را برمی گرداند. : برای ساخت و سازیا فقط تابع توزیع. در این حالت، می توانید احتمال اینکه تعداد عناصر خوب در یک نمونه از یک محدوده خاص، مثلاً 2 یا کمتر (شامل 0) باشد، محاسبه کنید.
برای این کار باید فرمول = = را بنویسید BINOM.DIST(2; 10; 0.1; TRUE)
ب: برای یک مقدار غیرصحیح x، . به عنوان مثال، فرمول های زیرهمان مقدار را برمی گرداند: =BINOM.DIST( 2 ; 10; 0.1; درست)=BINOM.DIST( 2,9 ; 10; 0.1; درست)
ب: در فایل نمونه چگالی احتمالو تابع توزیعهمچنین با استفاده از تعریف و تابع NUMBERCOMB() محاسبه می شود.
شاخص های توزیع
در نمونه فایل در کاربرگ مثالفرمول هایی برای محاسبه برخی از شاخص های توزیع وجود دارد:
- =n*p;
- (انحراف استاندارد مربع) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
بیایید فرمول را استخراج کنیم انتظارات ریاضیتوزیع دو جمله ایبا استفاده از مدار برنولی .
طبق تعریف، متغیر تصادفی X است طرح برنولی(متغیر تصادفی برنولی) دارد تابع توزیع :

این توزیع نامیده می شود توزیع برنولی .
ب : توزیع برنولی- مورد خاص توزیع دو جمله ایبا پارامتر n=1.
بیایید 3 آرایه 100 عددی با احتمال موفقیت متفاوت ایجاد کنیم: 0.1; 0.5 و 0.9. برای انجام این کار در پنجره تولید اعداد تصادفیاجازه دهید پارامترهای زیر را برای هر احتمال p تنظیم کنیم:

ب: اگر گزینه را تنظیم کنید پراکندگی تصادفی (دانه تصادفی، سپس می توانید مجموعه تصادفی خاصی از اعداد تولید شده را انتخاب کنید. به عنوان مثال، با تنظیم این گزینه = 25، می توانید مجموعه های مشابهی از اعداد تصادفی را در رایانه های مختلف تولید کنید (البته اگر سایر پارامترهای توزیع یکسان باشند). مقدار گزینه می تواند مقادیر صحیح را از 1 تا 32767 بگیرد پراکندگی تصادفیممکن است گیج کننده باشد بهتر است به این صورت ترجمه شود شماره گیری با اعداد تصادفی .
در نتیجه ما 3 ستون 100 عددی خواهیم داشت که بر اساس آنها می توانیم به عنوان مثال احتمال موفقیت را تخمین بزنیم. صطبق فرمول: تعداد موفقیت/100(سانتی متر برگه فایل نمونه GenerationBernoulli).

ب: برای توزیع های برنولیبا p=0.5 می توانید از فرمول =RANDBETWEEN(0;1) استفاده کنید که با .
تولید اعداد تصادفی توزیع دو جمله ای
فرض کنید 7 محصول معیوب در نمونه وجود دارد. این به این معنی است که "بسیار محتمل" است که نسبت محصولات معیوب تغییر کرده باشد صکه از ویژگی های فرآیند تولید ماست. اگرچه چنین وضعیتی "بسیار محتمل" است، اما این احتمال وجود دارد (خطر آلفا، خطای نوع 1، "زنگ هشدار نادرست") صبدون تغییر باقی ماند و افزایش تعداد محصولات معیوب به دلیل نمونه گیری تصادفی بود.
همانطور که در شکل زیر مشاهده می شود، 7 تعداد محصولات معیوب قابل قبول برای فرآیندی با 0.21=p در همان مقدار است. آلفا. این نشان می دهد که وقتی از مقدار آستانه اقلام معیوب در یک نمونه فراتر رفت، ص"به احتمال زیاد" افزایش یافته است. عبارت "به احتمال زیاد" به این معنی است که تنها به احتمال 10٪ (100٪ - 90٪) وجود دارد که انحراف درصد محصولات معیوب بالاتر از آستانه فقط به دلایل تصادفی باشد.
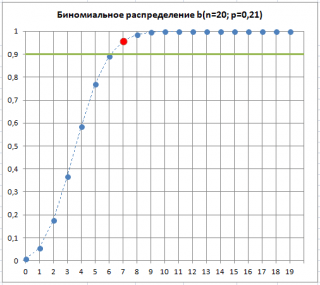
بنابراین، فراتر رفتن از آستانه تعداد محصولات معیوب در نمونه می تواند به عنوان سیگنالی باشد که فرآیند به هم ریخته و شروع به تولید محصولات مستعمل کرده است. Oدرصد بالاتر محصولات معیوب
ب: قبل از MS EXCEL 2010، EXCEL یک تابع CRITBINOM() داشت که معادل BINOM.INV().
CRITBINOM() در MS EXCEL 2010 و بالاتر برای سازگاری باقی مانده است.
رابطه توزیع دو جمله ای با سایر توزیع ها nتوزیع دو جمله ایاگر پارامتر صبه بی نهایت تمایل دارد و توزیع دو جمله ایبه 0 تمایل دارد، سپس در این مورد می توان تقریب زد. ما می توانیم شرایط را زمانی که تقریب فرموله کنیمتوزیع پواسون
- صخوب کار می کند: ص(هر چه کمتر nو بیشتر
- ص >0,9 ، هر چه تقریب دقیق تر باشد) q =1- ص(با توجه به اینکه q، محاسبات در این مورد باید از طریق انجام شود X(الف n - xنیاز به تعویض دارد q(هر چه کمتر n). بنابراین، هر چه کمتر
، هر چه تقریب دقیق تر باشد). توزیع دو جمله ایدر 0.110
می توان تقریب زد. توزیع دو جمله ایبه نوبه خود، هنگامی که اندازه جمعیت N باشد، ممکن است به عنوان یک تقریب خوب عمل کندتوزیع فرا هندسی
بسیار بزرگتر از اندازه نمونه n (یعنی N>>n یا n/N می توانید در مورد رابطه بین توزیع های بالا در مقاله بیشتر بخوانید. نمونه هایی از تقریب نیز در آنجا آورده شده است، و شرایط زمانی که ممکن است و با چه دقتی توضیح داده شده است.مشاوره
: می توانید در مورد سایر توزیع های MS EXCEL در مقاله بخوانید. توزیع دو جمله ای یکی از مهم ترین توزیع های احتمال یک متغیر گسسته است. توزیع دو جمله ای توزیع احتمال عدد است متروقوع یک رویداد الف V nمشاهدات مستقل متقابل. اغلب یک رویداد الف"موفقیت" یک مشاهده نامیده می شود و رویداد مخالف "شکست" نامیده می شود، اما این نامگذاری بسیار مشروط است.
شرایط توزیع دو جمله ای:
- در مجموع انجام شد nآزمایشاتی که در آن رویداد الفممکن است رخ دهد یا نباشد؛
- رویداد الفدر هر آزمایشی می تواند با همان احتمال رخ دهد ص;
- تست ها متقابل مستقل هستند.
احتمال اینکه در nرویداد تست الفدقیقا خواهد آمد متربار را می توان با استفاده از فرمول برنولی محاسبه کرد:
![]()
کجا ص- احتمال وقوع یک رویداد الف;
q = 1 - ص- احتمال وقوع رویداد مخالف.
بیایید آن را بفهمیم چرا توزیع دوجمله ای با فرمول برنولی به روشی که در بالا توضیح داده شد مرتبط است؟ . رویداد - تعداد موفقیت ها در nآزمون ها به تعدادی گزینه تقسیم می شوند که در هر کدام موفقیت حاصل می شود مترتست ها و شکست - در n - مترتست ها بیایید یکی از این گزینه ها را در نظر بگیریم - ب1 . با استفاده از قانون جمع کردن احتمالات، احتمالات وقایع متضاد را ضرب می کنیم:
![]() ,
,
و اگر اشاره کنیم q = 1 - ص، آن
![]() .
.
هر گزینه دیگری که در آن مترموفقیت و n - مترشکست ها تعداد چنین گزینه هایی برابر با تعداد راه هایی است که فرد می تواند nتست گرفتن مترموفقیت
مجموع همه احتمالات متراعداد وقوع رویداد الف(اعداد از 0 تا n) برابر با یک است:

که در آن هر جمله بیانگر یک عبارت در دوجمله ای نیوتن است. بنابراین توزیع مورد نظر را توزیع دو جمله ای می نامند.
در عمل، اغلب لازم است که احتمالات را "بیشتر از مترموفقیت در nتست ها» یا «حداقل مترموفقیت در nبرای این کار از فرمول های زیر استفاده می شود.
تابع انتگرال، یعنی احتمال اف(متر) آنچه در آن است nرویداد رصدی الفدیگر نخواهد آمد متریک باررا می توان با استفاده از فرمول محاسبه کرد:
به نوبه خود احتمال اف(≥متر) آنچه در آن است nرویداد رصدی الفکمتر نخواهد آمد متریک بار، با فرمول محاسبه می شود:
گاهی اوقات محاسبه احتمال آن راحت تر است nرویداد رصدی الفدیگر نخواهد آمد متربارها، از طریق احتمال رویداد مخالف:
![]() .
.
اینکه کدام فرمول استفاده شود بستگی به این دارد که مجموع عبارتهای کمتری در کدام یک از آنها باشد.
مشخصات توزیع دو جمله ای با استفاده از فرمول های زیر محاسبه می شود .
انتظارات ریاضی: .
پراکندگی: .
انحراف معیار: .
توزیع دو جمله ای و محاسبات در MS Excel
احتمال دو جمله ای پ n ( متر) و مقادیر تابع انتگرال اف(متر) را می توان با استفاده از تابع MS Excel BINOM.DIST محاسبه کرد. پنجره محاسبه مربوطه در زیر نشان داده شده است (برای بزرگنمایی کلیک چپ کنید).

MS Excel از شما می خواهد که داده های زیر را وارد کنید:
- تعداد موفقیت ها؛
- تعداد تست ها؛
- احتمال موفقیت؛
- انتگرال - مقدار منطقی: 0 - اگر نیاز به محاسبه احتمال دارید پ n ( متر) و 1 - در صورت احتمال اف(متر).
مثال 1.مدیر شرکت اطلاعات مربوط به تعداد دوربین های فروخته شده در 100 روز گذشته را خلاصه کرد. این جدول اطلاعات را خلاصه می کند و احتمال فروش تعداد معینی دوربین در روز را محاسبه می کند.
اگر 13 دوربین یا بیشتر فروخته شود روز با سود به پایان می رسد. احتمال اینکه روز سودآوری داشته باشد:
![]()
احتمال اینکه یک روز بدون سود کار شود:
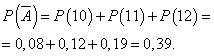
اجازه دهید احتمال اینکه یک روز با سود کار می شود ثابت و برابر با 0.61 باشد و تعداد دوربین های فروخته شده در روز به روز بستگی ندارد. سپس میتوانیم از توزیع دوجملهای استفاده کنیم، جایی که رویداد الف- روز با سود کار خواهد شد، - بدون سود.
احتمال اینکه تمام 6 روز با سود کار شود:
![]() .
.
ما با استفاده از تابع MS Excel BINOM.DIST همان نتیجه را دریافت می کنیم (مقدار انتگرال 0 است):
پ 6 (6 ) = BINOM.DIST(6; 6; 0.61; 0) = 0.052.
احتمال اینکه از 6 روز 4 روز یا بیشتر با سود کار شود:
کجا ![]() ,
,
![]() ,
,
با استفاده از تابع MS Excel BINOM.DIST، این احتمال را محاسبه می کنیم که از 6 روز بیش از 3 روز با سود کامل نمی شود (مقدار مقدار انتگرال 1 است):
پ 6 (≤3 ) = BINOM.DIST(3; 6; 0.61; 1) = 0.435.
احتمال اینکه تمام 6 روز با ضرر انجام شود:
![]() ,
,
میتوانیم همان شاخص را با استفاده از تابع MS Excel BINOM.DIST محاسبه کنیم:
پ 6 (0 ) = BINOM.DIST(0; 6; 0.61; 0) = 0.0035.
خودتان مشکل را حل کنید و سپس راه حل را ببینید
مثال 2. 2 توپ سفید و 3 گلوله سیاه در کوزه وجود دارد. یک توپ از کوزه بیرون آورده می شود، رنگ آن تنظیم می شود و دوباره قرار می گیرد. تلاش 5 بار تکرار می شود. تعداد وقوع توپ های سفید یک متغیر تصادفی گسسته است X، بر اساس قانون دوجمله ای توزیع شده است. قانون توزیع یک متغیر تصادفی را ترسیم کنید. حالت، انتظارات ریاضی و پراکندگی را تعریف کنید.
بیایید با هم به حل مشکلات ادامه دهیم
مثال 3.از پیک به سایت ها رفتیم n= 5 پیک. هر پیک محتمل است ص= 0.3، صرف نظر از دیگران، برای شی دیر است. متغیر تصادفی گسسته X- تعداد پیک های دیررس یک سری توزیع برای این متغیر تصادفی بسازید. انتظارات ریاضی، واریانس، انحراف معیار آن را بیابید. این احتمال را پیدا کنید که حداقل دو پیک برای اشیا تاخیر داشته باشند.
در این پست و چند پست بعدی به مدل های ریاضی رویدادهای تصادفی خواهیم پرداخت. مدل ریاضییک عبارت ریاضی است که یک متغیر تصادفی را نشان می دهد. برای متغیرهای تصادفی گسسته، این عبارت ریاضی به عنوان تابع توزیع شناخته می شود.
اگر مشکل به شما اجازه می دهد که به صراحت یک عبارت ریاضی را که نشان دهنده یک متغیر تصادفی است بنویسید، می توانید احتمال دقیق هر یک از مقادیر آن را محاسبه کنید. در این حالت می توانید تمام مقادیر تابع توزیع را محاسبه و فهرست کنید. توزیع های متنوعی از متغیرهای تصادفی در کاربردهای تجاری، جامعه شناختی و پزشکی مشاهده می شود. یکی از مفیدترین توزیع ها دو جمله ای است.
توزیع دو جمله ایبرای شبیه سازی موقعیت هایی که با ویژگی های زیر مشخص می شوند استفاده می شود.
- نمونه از تعداد ثابتی از عناصر تشکیل شده است n، نشان دهنده نتایج یک آزمون خاص است.
- هر عنصر نمونه متعلق به یکی از دو دسته متقابل منحصر به فرد است که کل فضای نمونه را خسته می کند. به طور معمول این دو دسته موفقیت و شکست نامیده می شوند.
- احتمال موفقیت rثابت است بنابراین، احتمال شکست است 1 - ص.
- نتیجه (یعنی موفقیت یا شکست) هر آزمایشی به نتیجه آزمایش دیگری بستگی ندارد. برای اطمینان از استقلال نتایج، عناصر نمونه معمولاً با استفاده از دو روش مختلف به دست میآیند. هر عنصر در نمونه به طور تصادفی از یک جمعیت نامتناهی بدون بازگشت یا از یک جمعیت محدود با بازگشت استخراج میشود.
یادداشت را با فرمت یا نمونه ها در قالب دانلود کنید
توزیع دو جمله ای برای تخمین تعداد موفقیت ها در یک نمونه متشکل از استفاده می شود nمشاهدات بیایید سفارش را به عنوان مثال در نظر بگیریم. مشتریان شرکت ساکسون برای ثبت سفارش می توانند از فرم الکترونیکی تعاملی استفاده کرده و برای شرکت ارسال کنند. سپس سیستم اطلاعاتی خطا، اطلاعات ناقص یا نادرست در سفارشات را بررسی می کند. هر سفارش مورد نظر علامت گذاری شده و در گزارش استثنای روزانه گنجانده شده است. داده های جمع آوری شده توسط شرکت نشان می دهد که احتمال خطا در سفارشات 0.1 است. یک شرکت مایل است بداند که احتمال یافتن تعداد معینی از سفارشات اشتباه در یک نمونه مشخص چقدر است. به عنوان مثال، فرض کنید مشتریان چهار را تکمیل کردند فرم های الکترونیکی. احتمال اینکه همه سفارشات بدون خطا باشد چقدر است؟ چگونه این احتمال را محاسبه کنیم؟ با موفقیت، خطا را هنگام پر کردن فرم درک خواهیم کرد و سایر نتایج شکست تلقی خواهند شد. به یاد داشته باشید که ما به تعداد سفارشات اشتباه در یک نمونه معین علاقه مند هستیم.
چه نتایجی را می توانیم مشاهده کنیم؟ اگر نمونه از چهار مرتبه تشکیل شده باشد، ممکن است یک، دو، سه یا هر چهار مرتبه نادرست باشد و ممکن است همه آنها صحیح باشند. آیا یک متغیر تصادفی که تعداد فرم های اشتباه تکمیل شده را توصیف می کند، می تواند مقدار دیگری داشته باشد؟ این امکان پذیر نیست زیرا تعداد فرم های نادرست نمی تواند از حجم نمونه بیشتر شود nیا منفی باشد بنابراین، یک متغیر تصادفی که از قانون توزیع دوجمله ای پیروی می کند، مقادیری از 0 تا را می گیرد n.
فرض کنید در یک نمونه از چهار مرتبه نتایج زیر مشاهده می شود:
احتمال یافتن سه مرتبه اشتباه در یک نمونه چهار مرتبه، به ترتیب مشخص شده چقدر است؟ از آنجایی که مطالعات اولیهنشان داد که احتمال خطا هنگام پر کردن فرم 0.10 است، احتمال نتایج فوق به صورت زیر محاسبه می شود:
از آنجایی که نتایج به یکدیگر وابسته نیستند، احتمال توالی مشخص شده از نتایج برابر است با: p*p*(1–p)*p = 0.1*0.1*0.9*0.1 = 0.0009. اگر نیاز به محاسبه تعداد انتخاب دارید X nعناصر، باید از فرمول ترکیبی (1) استفاده کنید:

کجا n! = n * (n –1) * (n – 2) * … * 2 * 1 - فاکتوریل یک عدد n، و 0! = 1 و 1! = 1 طبق تعریف
این عبارت اغلب به عنوان . بنابراین، اگر n = 4 و X = 3 باشد، تعداد دنباله های متشکل از سه عنصر استخراج شده از حجم نمونه 4 با فرمول زیر تعیین می شود:
بنابراین، احتمال تشخیص سه دستور اشتباه به صورت زیر محاسبه می شود:
(تعداد دنباله های ممکن) *
(احتمال یک دنباله خاص) = 4 * 0.0009 = 0.0036
به همین ترتیب، می توانید احتمال اینکه از بین چهار ترتیب یک یا دو اشتباه وجود داشته باشد و همچنین احتمال اشتباه بودن یا درست بودن همه ترتیبات را محاسبه کنید. اما با افزایش حجم نمونه nتعیین احتمال یک توالی خاص از نتایج دشوارتر می شود. در این صورت مناسب است مدل ریاضی، توزیع دوجمله ای تعداد انتخاب ها را توصیف می کند Xاشیاء از یک انتخاب شامل nعناصر
توزیع دو جمله ای

کجا P(X)- احتمال Xموفقیت برای یک حجم نمونه معین nو احتمال موفقیت r, X = 0, 1, … n.
لطفاً توجه داشته باشید که فرمول (2) رسمی سازی نتیجه گیری های شهودی است. متغیر تصادفی X، که از توزیع دو جمله ای تبعیت می کند، می تواند هر عدد صحیحی را در محدوده 0 تا داشته باشد n. کار کنید rX(1 – p)n – Xنشان دهنده احتمال یک دنباله خاص متشکل از Xموفقیت در حجم نمونه برابر است n. مقدار تعداد ترکیبات ممکن را تعیین می کند Xموفقیت در nتست ها بنابراین، برای تعداد معینی از آزمایشات nو احتمال موفقیت rاحتمال یک دنباله متشکل از Xموفقیت، برابر
P(X) = (تعداد دنباله های ممکن) * (احتمال یک دنباله خاص) = 
بیایید مثال هایی را در نظر بگیریم که کاربرد فرمول (2) را نشان می دهند.
1. فرض کنید احتمال پرکردن اشتباه فرم 0.1 باشد. احتمال اینکه از بین چهار فرم تکمیل شده، سه مورد نادرست باشد چقدر است؟ با استفاده از فرمول (2) متوجه می شویم که احتمال تشخیص سه مرتبه اشتباه در نمونه ای متشکل از چهار مرتبه برابر است با
2. فرض کنید احتمال پرکردن نادرست فرم 0.1 باشد. احتمال اینکه از بین چهار فرم تکمیل شده حداقل سه مورد نادرست باشد چقدر است؟ همانطور که در مثال قبل نشان داده شد، احتمال اینکه از بین چهار فرم تکمیل شده، سه فرم نادرست باشد 0.0036 است. برای محاسبه احتمال اینکه از بین چهار فرم تکمیل شده حداقل سه فرم نادرست باشد، باید احتمال اینکه از بین چهار فرم تکمیل شده سه نادرست باشد و احتمال اینکه از بین چهار فرم تکمیل شده همه نادرست باشند را اضافه کنید. احتمال رخداد دوم است
بنابراین، احتمال اینکه از بین چهار فرم تکمیل شده حداقل سه مورد نادرست باشد برابر است
P(X > 3) = P(X = 3) + P(X = 4) = 0.0036 + 0.0001 = 0.0037
3. فرض کنید احتمال پرکردن اشتباه فرم 0.1 باشد. احتمال اینکه از چهار فرم تکمیل شده کمتر از سه فرم نادرست باشد چقدر است؟ احتمال این اتفاق
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
با استفاده از فرمول (2) هر یک از این احتمالات را محاسبه می کنیم:

بنابراین، P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
احتمال P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. سپس P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
با افزایش حجم نمونه nمحاسبات مشابه آنچه در مثال 3 انجام شد دشوار می شود. برای جلوگیری از این عوارض، بسیاری از احتمالات دو جمله ای از قبل جدول بندی شده اند. برخی از این احتمالات در شکل نشان داده شده است. 1. مثلاً برای بدست آوردن این احتمال که X= 2 در n= 4 و ص= 0.1، باید عددی را که در تقاطع خط قرار دارد از جدول استخراج کنید X= 2 و ستون r = 0,1.

برنج. 1. احتمال دو جمله ای در n = 4, X= 2 و r = 0,1
توزیع دوجمله ای را می توان با استفاده از تابع Excel =BINOM.DIST() (شکل 2) محاسبه کرد که دارای 4 پارامتر است: تعداد موفقیت ها - Xتعداد تست ها (یا حجم نمونه) – nاحتمال موفقیت – r، پارامتر انتگرال، که مقدار TRUE را می گیرد (در این حالت احتمال محاسبه می شود نه کمتر Xرویدادها) یا FALSE (در این مورد احتمال محاسبه می شود دقیقا Xرویدادها).

برنج. 2. پارامترهای تابع =BINOM.DIST()
برای سه مثال بالا، محاسبات در شکل نشان داده شده است. 3 (به فایل اکسل نیز مراجعه کنید). هر ستون شامل یک فرمول است. اعداد پاسخ نمونه های عدد مربوطه را نشان می دهند).

برنج. 3. محاسبه توزیع دو جمله ای در اکسل برای n= 4 و ص = 0,1
ویژگی های توزیع دو جمله ای
توزیع دو جمله ای به پارامترها بستگی دارد nو r. توزیع دو جمله ای می تواند متقارن یا نامتقارن باشد. اگر p = 0.05، توزیع دوجمله ای بدون توجه به مقدار پارامتر متقارن است. n. با این حال، اگر p ≠ 0.05، توزیع کج می شود. هر چه مقدار پارامتر نزدیکتر باشد rبه 0.05 و اندازه نمونه بزرگتر است n، عدم تقارن توزیع کمتر مشخص می شود. بنابراین، توزیع تعداد فرم های نادرست تکمیل شده به سمت راست منحرف می شود زیرا ص= 0.1 (شکل 4).

برنج. 4. هیستوگرام توزیع دوجمله ای در n= 4 و ص = 0,1
انتظار توزیع دوجمله ایبرابر حاصلضرب حجم نمونه nدر مورد احتمال موفقیت r:
(3) M = E(X) =n.p.
به طور متوسط، با یک سری آزمایش به اندازه کافی طولانی در یک نمونه متشکل از چهار مرتبه، ممکن است P = E(X) = 4 x 0.1 = 0.4 فرم های اشتباه تکمیل شده وجود داشته باشد.
انحراف استاندارد توزیع دو جمله ای
به عنوان مثال، انحراف معیار تعداد فرم های اشتباه تکمیل شده در یک حسابداری سیستم اطلاعاتیبرابر است با:
از مطالب کتاب Levin et al Statistics for Manager استفاده شده است. - م.: ویلیامز، 2004. - ص. 307-313
نظریه احتمال به طور نامرئی در زندگی ما وجود دارد. ما به آن توجه نمی کنیم، اما هر اتفاقی در زندگی ما یک احتمال یا احتمال دیگری دارد. با در نظر گرفتن تعداد زیاد سناریوهای ممکن، لازم است محتمل ترین و کم احتمال ترین آنها را مشخص کنیم. تحلیل گرافیکی چنین داده های احتمالی راحت تر است. توزیع می تواند در این امر به ما کمک کند. Binomial یکی از ساده ترین و دقیق ترین است.
قبل از اینکه مستقیماً به ریاضیات و نظریه احتمالات برویم، بیایید بفهمیم چه کسی اولین کسی بود که این نوع توزیع را ارائه کرد و تاریخچه توسعه دستگاه ریاضی برای این مفهوم چیست.
داستان
مفهوم احتمال از زمان های قدیم شناخته شده است. با این حال، ریاضیدانان باستان اهمیت چندانی برای آن قائل نبودند و تنها توانستند پایه های نظریه ای را که بعداً به نظریه احتمال تبدیل شد، پایه ریزی کنند. آنها برخی از روش های ترکیبی را ایجاد کردند که به کسانی که بعداً خود نظریه را ایجاد و توسعه دادند، بسیار کمک کرد.
در نیمه دوم قرن هفدهم، شکل گیری مفاهیم و روش های اساسی نظریه احتمال آغاز شد. تعاریف متغیرهای تصادفی و روشهایی برای محاسبه احتمال رخدادهای مستقل و وابسته ساده و چند پیچیده معرفی شد. این علاقه به متغیرهای تصادفی و احتمالات توسط قمار دیکته می شد: هر شخصی می خواست بداند شانس او برای برنده شدن در بازی چقدر است.
مرحله بعدی به کارگیری روش های تحلیل ریاضی در نظریه احتمالات بود. ریاضیدانان برجسته ای مانند لاپلاس، گاوس، پواسون و برنولی این وظیفه را بر عهده گرفتند. آنها بودند که این حوزه از ریاضیات را به سطح جدیدی ارتقا دادند. این جیمز برنولی بود که قانون توزیع دوجمله ای را کشف کرد. به هر حال، همانطور که بعداً متوجه خواهیم شد، بر اساس این کشف چندین مورد دیگر ساخته شد که امکان ایجاد قانون توزیع نرمال و بسیاری موارد دیگر را فراهم کرد.
اکنون، قبل از شروع توصیف توزیع دوجملهای، کمی حافظه خود را از مفاهیم نظریه احتمال که احتمالاً قبلاً از مدرسه فراموش کردهایم، تجدید میکنیم.
مبانی نظریه احتمال
ما چنین سیستم هایی را در نظر خواهیم گرفت که در نتیجه تنها دو نتیجه ممکن است: "موفقیت" و "شکست". درک این موضوع با یک مثال آسان است: ما یک سکه پرتاب می کنیم، به این امید که سرها بالا بیاید. احتمال هر یک از رویدادهای ممکن (سقوط سر - "موفقیت"، سقوط سر - "شکست") برابر با 50 درصد است اگر سکه کاملاً متعادل باشد و هیچ عامل دیگری وجود نداشته باشد که ممکن است بر آزمایش تأثیر بگذارد.
این ساده ترین اتفاق بود. اما وجود دارند سیستم های پیچیده، که در آن اقدامات متوالی انجام می شود و احتمال نتایج این اقدامات متفاوت خواهد بود. به عنوان مثال، سیستم زیر را در نظر بگیرید: در جعبه ای که محتوای آن را نمی بینیم، شش توپ کاملاً یکسان، سه جفت رنگ آبی، قرمز و سفید وجود دارد. باید به صورت تصادفی چند توپ بدست آوریم. بر این اساس، با بیرون کشیدن یکی از توپهای سفید، احتمال اینکه در مرحله بعد نیز به توپ سفید برسیم، به میزان قابل توجهی کاهش میدهیم. این اتفاق می افتد زیرا تعداد اشیاء در سیستم تغییر می کند.
در بخش بعدی، مفاهیم پیچیده تری ریاضی را بررسی خواهیم کرد که ما را به کلمات " نزدیک تر می کند. توزیع نرمال"، "توزیع دو جمله ای" و مانند آن.

عناصر آمار ریاضی
در آمار که یکی از حوزههای کاربرد نظریه احتمالات است، مثالهای زیادی وجود دارد که دادههایی برای تجزیه و تحلیل به صراحت ارائه نشده است. یعنی نه به صورت عددی، بلکه به صورت تقسیم بر اساس خصوصیات، مثلاً بر اساس جنسیت. برای استفاده از ابزارهای ریاضی برای چنین دادههایی و نتیجهگیری از نتایج بهدستآمده، لازم است دادههای اصلی را به فرمت عددی تبدیل کنیم. به طور معمول، برای انجام این کار، به یک نتیجه مثبت مقدار 1 و به یک نتیجه منفی مقدار 0 اختصاص داده می شود. بنابراین، داده های آماری را به دست می آوریم که می توانند با استفاده از روش های ریاضی تجزیه و تحلیل شوند.
گام بعدی برای درک اینکه توزیع دوجمله ای یک متغیر تصادفی چیست، تعیین واریانس متغیر تصادفی و انتظار ریاضی است. در بخش بعدی در این مورد صحبت خواهیم کرد.

انتظار
در واقع، درک اینکه انتظارات ریاضی چیست دشوار نیست. سیستمی را در نظر بگیرید که در آن رویدادهای مختلف با احتمالات متفاوت خود وجود دارد. انتظار ریاضی کمیت خواهد بود برابر با مجموعمحصولات مقادیر این رویدادها (به شکل ریاضی که در بخش آخر بحث کردیم) با احتمال وقوع آنها.
انتظارات ریاضی یک توزیع دوجمله ای با استفاده از همین طرح محاسبه می شود: مقدار یک متغیر تصادفی را می گیریم، آن را در احتمال یک نتیجه مثبت ضرب می کنیم و سپس داده های حاصل را برای همه متغیرها جمع می کنیم. ارائه این داده ها به صورت گرافیکی بسیار راحت است - به این ترتیب تفاوت بین انتظارات ریاضی مقادیر مختلف بهتر درک می شود.
در بخش بعدی کمی در مورد مفهوم دیگری به شما خواهیم گفت - واریانس یک متغیر تصادفی. همچنین ارتباط نزدیکی با مفهوم توزیع احتمال دو جمله ای دارد و مشخصه آن است.

واریانس توزیع دو جمله ای
این مقدار ارتباط نزدیکی با مقدار قبلی دارد و همچنین توزیع داده های آماری را مشخص می کند. این نشان دهنده میانگین مربع انحراف مقادیر از انتظارات ریاضی آنها است. یعنی واریانس یک متغیر تصادفی مجموع مجذور اختلافات بین مقدار متغیر تصادفی و آن است. انتظارات ریاضیضرب در احتمال این رویداد.
به طور کلی، این تنها چیزی است که ما باید در مورد واریانس بدانیم تا بفهمیم توزیع احتمال دو جمله ای چیست. حالا بیایید مستقیماً به موضوع اصلی خود برویم. یعنی چه چیزی در پس چنین عبارت به ظاهر نسبتاً پیچیده "قانون توزیع دوجمله ای" نهفته است.

توزیع دو جمله ای
بیایید ابتدا بفهمیم که چرا این توزیع دو جمله ای است. از کلمه "بینوم" می آید. شاید نام دوجمله ای نیوتن را شنیده باشید - فرمولی که می توان از آن برای گسترش مجموع هر دو عدد a و b به هر توان غیر منفی n استفاده کرد.
همانطور که احتمالاً قبلاً حدس زده اید، فرمول دو جمله ای نیوتن و فرمول توزیع دو جمله ای تقریباً فرمول های مشابهی هستند. با تنها استثنا که دومی برای کمیت های خاص اهمیت عملی دارد و اولی فقط یک ابزار ریاضی عمومی است که کاربردهای آن در عمل می تواند متفاوت باشد.
فرمول های توزیع
تابع توزیع دو جمله ای را می توان به صورت مجموع عبارت های زیر نوشت:
(n!/(n-k)!k!)*p k *q n-k
در اینجا n تعداد آزمایشهای تصادفی مستقل، p تعداد نتایج موفقیتآمیز، q تعداد نتایج ناموفق، k تعداد آزمایش است (میتواند مقادیری از 0 تا n بگیرد)! - تعیین فاکتوریل، تابعی از عددی که مقدار آن برابر است با حاصلضرب تمام اعدادی که قبل از آن قرار می گیرند (مثلاً برای عدد 4: 4!=1*2*3*4=24).
علاوه بر این، تابع توزیع دو جمله ای را می توان به عنوان یک تابع بتا ناقص نوشت. با این حال، این یک تعریف پیچیده تر است، که تنها در هنگام حل مسائل آماری پیچیده استفاده می شود.
توزیع دوجمله ای، که نمونه هایی از آن را در بالا بررسی کردیم، یکی از بهترین هاست انواع سادهتوزیع ها در نظریه احتمال یک توزیع نرمال نیز وجود دارد که نوعی دوجمله ای است. بیشتر مورد استفاده قرار می گیرد و محاسبه آن ساده ترین است. همچنین توزیع برنولی، توزیع پواسون و توزیع شرطی وجود دارد. همه آنها به صورت گرافیکی محدوده احتمال یک فرآیند خاص را در شرایط مختلف مشخص می کنند.
در بخش بعدی جنبه های مربوط به استفاده از این دستگاه ریاضی را در نظر خواهیم گرفت زندگی واقعی. البته در نگاه اول به نظر می رسد که این فقط یک چیز ریاضی دیگری است که طبق معمول در زندگی واقعی کاربرد پیدا نمی کند و به طور کلی به جز خود ریاضیدانان مورد نیاز کسی نیست. با این حال، این دور از مورد است. از این گذشته ، همه انواع توزیع ها و نمایش های گرافیکی آنها منحصراً برای اهداف عملی ایجاد شده اند و نه به عنوان یک هوی و هوس دانشمندان.

کاربرد
البته مهمترین کاربرد توزیع ها در آمار است، زیرا آنها نیازمند تجزیه و تحلیل پیچیده بسیاری از داده ها هستند. همانطور که تمرین نشان می دهد، بسیاری از مجموعه های داده تقریباً دارای توزیع مقادیر یکسانی هستند: مناطق بحرانی با مقادیر بسیار کم و بسیار بالا، به عنوان یک قاعده، حاوی عناصر کمتری نسبت به مقادیر متوسط هستند.
تجزیه و تحلیل مجموعه داده های بزرگ نه تنها در آمار مورد نیاز است. ضروری است، به عنوان مثال، در شیمی فیزیک. در این علم برای تعیین کمیت های زیادی که با ارتعاشات و حرکات تصادفی اتم ها و مولکول ها مرتبط هستند، استفاده می شود.
در بخش بعدی خواهیم فهمید که استفاده از مفاهیم آماری مانند دو جمله ای چقدر اهمیت دارد توزیع یک متغیر تصادفی در زندگی روزمرهبرای من و تو

چرا به این نیاز دارم؟
بسیاری از افراد وقتی صحبت از ریاضیات می شود این سوال را از خود می پرسند. به هر حال، ریاضیات را بیهوده ملکه علوم نمی نامند. اساس فیزیک، شیمی، زیست شناسی، اقتصاد است و در هر یک از این علوم نیز از توزیعی استفاده می شود: توزیع دوجمله ای گسسته یا عادی، فرقی نمی کند. و اگر نگاه دقیق تری به دنیای اطراف خود بیندازیم، خواهیم دید که ریاضیات در همه جا استفاده می شود: در زندگی روزمره، در محل کار و حتی روابط انسانی را می توان در قالب داده های آماری ارائه و تجزیه و تحلیل کرد (به هر حال، این ، همان چیزی است که در سازمان های خاصی که درگیر جمع آوری اطلاعات هستند کار می کنند).
حالا بیایید کمی در مورد آنچه که باید انجام دهید صحبت کنیم اگر نیاز دارید در مورد این موضوع بسیار بیشتر از آنچه در این مقاله توضیح داده ایم بدانید.
اطلاعاتی که ما در این مقاله آورده ایم هنوز کامل نیست. تفاوت های ظریف زیادی در مورد اینکه توزیع چه شکلی می تواند داشته باشد وجود دارد. توزیع دوجمله ای، همانطور که قبلاً متوجه شدیم، یکی از انواع اصلی است که بر روی آن کل است آمار ریاضیو نظریه احتمال
اگر علاقه مند شدید، یا در رابطه با کار خود نیاز به دانستن خیلی بیشتر در مورد این موضوع دارید، باید ادبیات تخصصی مطالعه کنید. شما باید با یک دوره دانشگاهی شروع کنید تجزیه و تحلیل ریاضیو به بخش نظریه احتمال بروید. دانش سری نیز مفید خواهد بود، زیرا توزیع احتمال دوجمله ای چیزی بیش از یک سری عبارت های متوالی نیست.
نتیجه گیری
قبل از اتمام مقاله، می خواهیم یک نکته جالب دیگر را به شما بگوییم. این به طور مستقیم به موضوع مقاله ما و به طور کلی تمام ریاضیات مربوط می شود.
بسیاری از مردم می گویند که ریاضیات علمی بی فایده است و هیچ چیزی که در مدرسه خوانده اند برای آنها مفید نبوده است. اما دانش هرگز زائد نیست، و اگر چیزی در زندگی برای شما مفید نیست، به این معنی است که شما آن را به سادگی به خاطر نمی آورید. اگر دانش داشته باشید، آنها می توانند به شما کمک کنند، اما اگر ندارید، نمی توانید از آنها انتظار کمک داشته باشید.
بنابراین، ما به مفهوم توزیع دوجمله ای و تمام تعاریف مرتبط با آن نگاه کردیم و در مورد نحوه کاربرد آن در زندگی ما صحبت کردیم.
