La molecola del DNA è localizzata. DNA e geni. Nuovo sguardo al DNA
Basi biochimiche dell'ereditarietà.
Ruolo genetico degli acidi nucleici.
Gli acidi nucleici sono polimeri biologici presenti in tutte le cellule, da quelle primitive a quelle complesse. Furono scoperti per la prima volta da Johann Friedrich Miescher nel 1868 in cellule ricche di materiale nucleare (leucociti, sperma di salmone). Il termine “acidi nucleici” fu proposto nel 1889.
Esistono due tipi di acidi nucleici: DNA, RNA (ATP - mononucleotide). DNA e RNA sono molecole - matrici. Il DNA è contenuto circa 6*10 -12 g nelle cellule somatiche: nel nucleo, nei mitocondri. L'RNA fa parte dei ribosomi e si trova nel nucleo e nel citoplasma.
Lo studio e la prova del ruolo principale degli acidi nucleici nella trasmissione delle informazioni ereditarie sono stati effettuati su particelle virali. È noto che il virus del mosaico del tabacco è virulento per il tabacco e la piantaggine. La particella virale è composta per il 95% da proteine e per il 5% da acido nucleico. Il capside proteico nelle particelle virali è stato scambiato, ma dopo qualche tempo la proteina in entrambi i ceppi si è trasformata nella sua forma precedente.
Nei batteriofagi che infettano E. coli, le proteine del rivestimento dei fagi sono state marcate con S radioattivo e il DNA dei fagi è stato marcato con P radioattivo. In una cellula batterica infettata dal fago, si sono formate particelle fagiche che contenevano solo P radioattivo.
Struttura e funzioni delle molecole di DNA e RNA.
Gli acidi nucleici sono biopolimeri di struttura irregolare, i cui monomeri sono nucleotidi. Il nucleotide è costituito da residui di tre sostanze: acido fosforico, carboidrato - pentoso, base azotata. I nucleotidi del DNA contengono il carboidrato desossiribosio e l'RNA contiene ribosio. I residui delle basi azotate purine e pirimidiniche che compongono il DNA sono l'adenina, la guanina, la citosina, la timina. Le molecole di RNA contengono adenina, guanina, citosina e uracile.
I nucleotidi sono collegati tra loro attraverso il residuo di acido fosforico di un nucleotide e il carboidrato di un altro mediante un forte legame estere covalente, chiamato “ponte di ossigeno”. Il legame passa attraverso il 5° atomo di carbonio di un carboidrato di un nucleotide fino al 3° atomo di carbonio di un carboidrato di un altro nucleotide. La sequenza nucleotidica rappresenta la struttura primaria degli acidi nucleici. L'RNA è una singola catena polinucleotidica. La struttura del DNA è una doppia catena polinucleotidica, avvolta a spirale.
La struttura secondaria del DNA si forma quando compare un secondo filamento di DNA, disposto secondo il principio di complementarità rispetto al primo. La seconda catena è opposta alla prima (antiparallela). Le basi azotate si trovano su un piano perpendicolare al piano della molecola: assomiglia ad una scala a chiocciola. Le ringhiere di questa scala sono residui di acido fosforico e carboidrati, e i gradini sono basi azotate.
Le basi azotate che compongono ciascun nucleotide in catene dirette in modo opposto sono in grado di formare legami idrogeno complementari tra loro (a causa dei gruppi funzionali esistenti nella struttura di ciascuna base azotata). Il nucleotide adenilico è complementare alla timina, il guanile alla citosina e viceversa. Di per sé, questi legami sono fragili, ma una molecola di DNA “cucita” ripetutamente per tutta la sua lunghezza con tali legami rappresenta una connessione molto forte.
Complementarità- questa è la corrispondenza spazio-strutturale e chimica tra le basi azotate, che si adattano l'una all'altra "come la chiave di una serratura".
Una molecola di DNA può contenere 10 8 o più nucleotidi.
La struttura della molecola del DNA come una doppia elica antiparallela fu proposta nel 1953 dal biologo americano James Watson e dal fisico inglese Francis Crick.
La molecola del DNA di qualsiasi organismo vivente sul pianeta è costituita da soli quattro tipi di nucleotidi, che differiscono tra loro per le basi azotate che contengono: adenile, guanile, timina e citosina. In ciò versatilità DNA. La loro sequenza è diversa e il numero è infinito.
Per ogni specie di organismi viventi e per ciascun organismo separatamente, questa sequenza è individuale e rigorosamente specifica .
Peculiarità La struttura del DNA è che le sezioni chimicamente attive della molecola - basi azotate, sono immerse al centro dell'elica e formano legami complementari tra loro, e residui di desossiribosio e acido fosforico si trovano alla periferia e coprono l'accesso alle basi azotate - sono chimicamente inattivi. Questa struttura può mantenere la stabilità chimica per lungo tempo. Cos'altro è necessario per archiviare le informazioni ereditarie? Sono queste caratteristiche della struttura del DNA che determinano la sua capacità di codificare e riprodurre le informazioni genetiche.
La forte struttura del DNA è abbastanza difficile da distruggere. Tuttavia, ciò accade regolarmente nella cellula - durante la sintesi dell'RNA e il raddoppio della molecola di DNA stessa prima della divisione cellulare.
Duplicazione, replicazione del DNA inizia con il fatto che uno speciale enzima - la DNA polimerasi - svolge la doppia elica e la separa in filamenti separati - si forma una forcella di duplicazione. L'enzima agisce come una serratura su una cerniera. Su ciascuna catena a filamento singolo - le estremità appiccicose della forcella di duplicazione - una nuova catena viene sintetizzata dai nucleotidi liberi nel carioplasma secondo il principio di complementarità. In due nuove molecole di DNA, un filamento rimane il filamento madre originale, e il secondo rimane il nuovo filamento figlia. Di conseguenza, invece di una molecola di DNA, appaiono due molecole con la stessa esatta composizione nucleotidica di quella originale.
Nei sistemi viventi incontriamo un nuovo tipo di reazioni sconosciute nella natura inanimata. Si chiamano Reazioni di sintesi della matrice . La sintesi della matrice è come la fusione su una matrice: nuove molecole vengono sintetizzate esattamente secondo il piano stabilito nella struttura delle molecole esistenti. Queste reazioni garantiscono l'esatta sequenza delle unità monomeriche nei polimeri sintetizzati. I monomeri arrivano in una posizione specifica sulle molecole che fungono da matrice in cui avviene la reazione. Se tali reazioni avvenissero a seguito di collisioni casuali di molecole, procederebbero con una lentezza infinita. La sintesi di molecole complesse basata sul principio del modello viene effettuata in modo rapido e preciso con l'aiuto di enzimi. La sintesi del modello è alla base delle reazioni più importanti nella sintesi degli acidi nucleici e delle proteine. Il ruolo della matrice nella cellula è svolto da molecole di acidi nucleici DNA o RNA. Le molecole monomeriche da cui viene sintetizzato il polimero - nucleotidi o amminoacidi - secondo il principio di complementarità, si trovano e fissano sulla matrice in un ordine rigorosamente definito. Quindi le unità monomeriche vengono collegate in una catena polimerica e il polimero finito lascia la matrice. Successivamente, la matrice è pronta per l'assemblaggio di una nuova molecola polimerica esattamente identica.
Le reazioni di tipo matrice sono una caratteristica specifica di una cellula vivente. Sono la base della proprietà fondamentale di tutti gli esseri viventi: la capacità di riprodurre i propri simili.
Funzioni degli acidi nucleici– archiviazione e trasmissione di informazioni ereditarie. Le molecole di DNA codificano informazioni sulla struttura primaria della proteina. La sintesi delle molecole di mRNA avviene sulla matrice del DNA. Questo processo è chiamato "trascrizione". L'I-RNA nel processo di "traduzione" implementa le informazioni sotto forma di una sequenza di amminoacidi in una molecola proteica.
Il DNA di ogni cellula trasporta informazioni non solo sulle proteine strutturali che determinano la forma della cellula, ma anche su tutte le proteine enzimatiche, sulle proteine ormonali e su altre proteine, nonché sulla struttura di tutti i tipi di RNA.
Forse gli acidi nucleici forniscono vari tipi di memoria biologica: immunologica, neurologica, ecc. E svolgono anche un ruolo significativo nella regolazione dei processi biosintetici.
Informazioni correlate.
La prima prova del ruolo del DNA come portatore di informazioni ereditarie negli organismi ha attirato un'enorme attenzione sullo studio degli acidi nucleici. Nel 1869 F. Miescher isolò una sostanza speciale dai nuclei delle cellule, che chiamò nucleina. Dopo 20 anni questo nome venne sostituito dal termine acido nucleico. Nel 1924 R. Felgen sviluppò un metodo per il riconoscimento citologico degli acidi nucleici attraverso la loro colorazione specifica e dimostrò che il DNA è localizzato nei nuclei delle cellule e l'RNA nel citoplasma. Nel 1936 A.N. Belozersky e I.I. Dubrovskaya isolò il DNA nella sua forma pura dai nuclei delle cellule vegetali. All'inizio degli anni '30. Furono chiariti i principi chimici di base della struttura degli zuccheri degli acidi nucleici e nel 1953 fu creato un modello strutturale del DNA.
L'unità strutturale di base degli acidi nucleici è nucleotide, che consiste di tre parti chimicamente diverse collegate da legami covalenti (Fig. 5.2).
Riso. 5.2. Formule strutturali: UN- nucleotidi; B-DNA; V- RNA (vedi anche pag. 110)

Riso. 5.2. Fine. Formule strutturali: UN- nucleotidi; 6 -DNA; V-RNA
La prima parte è lo zucchero contenente cinque atomi di carbonio: desossiribosio nel DNA e ribosio nell'RNA.
La seconda parte del nucleotide, una base azotata purinica o pirimidinica, è legata covalentemente al primo atomo di carbonio dello zucchero, formando una struttura chiamata nucleoside. Il DNA contiene basi puriniche - adenina(A) e guanina(D) - e basi pirimidiniche - timina(T) e citosina(C). I nucleosidi corrispondenti sono chiamati deossiadenosina, deossiguanosina, deossitimidina e deossicitidina. L'RNA contiene le stesse basi puriniche del DNA, una base pirimidinica citosina, e al posto della timina contiene uracile(U); i nucleosidi corrispondenti sono chiamati adenosina, guanosina, uridina e citidina.
La terza parte del nucleotide è un gruppo fosfato, che collega i nucleosidi vicini in una catena polimerica attraverso legami fosfodiesterici tra l'atomo di 5 atomi di carbonio di uno zucchero e l'atomo di 3 atomi di carbonio di un altro (Fig. 5.2, b, V). Nucleotidi sono chiamati nucleosidi con uno o più gruppi fosfato attaccati mediante legami estere agli atomi di carbonio da 3" o 5 dello zucchero. La sintesi dei nucleotidi precede la sintesi degli acidi nucleici; di conseguenza, i nucleotidi sono prodotti dell'idrolisi chimica o enzimatica degli acidi nucleici.
Gli acidi nucleici sono catene polimeriche molto lunghe costituite da mononucleotidi collegati da legami 5 e 3'-fosfodiestere. Una molecola di DNA intatta contiene, a seconda del tipo di organismo, da diverse migliaia a molti milioni di nucleotidi, una molecola di RNA intatta - da 100 a 100 mila o più nucleotidi.
I risultati delle analisi di E. Chargaff sulla composizione nucleotidica del DNA di varie forme di specie hanno mostrato che il rapporto molecolare di varie basi azotate - adenina, guanina, timina, citosina - varia ampiamente. Di conseguenza, è stato dimostrato che il DNA non è affatto un polimero monotono costituito da tetranucleotidi identici, come si presumeva negli anni '40. XX secoli e che possiede pienamente la complessità necessaria per la conservazione e la trasmissione dell'informazione ereditaria sotto forma di una sequenza specifica di basi nucleotidiche.
La ricerca di E. Chargaff ha anche rivelato una caratteristica inerente a tutte le molecole di DNA: il contenuto molare di adenina è uguale al contenuto di timina e il contenuto molare di guanina è uguale al contenuto di citosina. Queste uguaglianze sono chiamate regola di equivalenza di Chargaff: [A] = [T], [G] = [C]; il numero di purine è uguale al numero di pirimidine. A seconda della specie cambia solo il rapporto ([A] + [T])/([G] + [C]) (Tabella 5.1).
|
Composizione delle basi |
Atteggiamento |
Asimmetria |
|||||
|
motivi |
|||||||
|
(A + T)/(SOL + C) |
|||||||
|
Animali |
|||||||
|
Tartaruga |
|||||||
|
granchio di mare |
|||||||
|
Riccio di mare |
|||||||
|
Piante, funghi |
|||||||
|
germe di grano |
|||||||
|
Fungo Aspergillus niger |
|||||||
|
Batteri |
|||||||
|
Escherichia coli |
|||||||
|
Staphylococcus aureus |
|||||||
|
Clostridium perfringens |
|||||||
|
Brucella abortita |
|||||||
|
Sarcina lutea |
|||||||
|
Batteriofagi |
|||||||
|
FH 174 (forma virale) |
|||||||
|
FH 174 (forma replicativa) |
|||||||
Si chiama il rapporto tra le basi coefficiente nucleotidico(specie) specificità. La scoperta di Chargaff formulò un'importante caratteristica strutturale del DNA, che fu successivamente riflessa nel modello strutturale del DNA di J. Watson e F. Crick (1953), che di fatto dimostrarono che le regole di Chargaff non impongono alcuna restrizione sul possibile numero di combinazioni di diverse sequenze di basi in grado di formare molecole di DNA.
Il concetto di specificità nucleotidica ha costituito la base di una nuova branca della biologia: sistematica genetica, che opera confrontando la composizione e la struttura degli acidi nucleici per costruire un sistema naturale di organismi.
Secondo il modello Watson-Crick, una molecola di DNA è costituita da due catene polinucleotidiche (fili, filamenti), collegate tra loro mediante legami idrogeno trasversali tra basi azotate secondo il principio complementare (l'adenina di una catena è collegata da due legami idrogeno con timina della catena opposta e guanina e citosina di catene diverse sono collegate tra loro da tre legami idrogeno). In questo caso, due catene polinucleotidiche di una molecola sono antiparallele, cioè di fronte all'estremità da 3" di una catena c'è l'estremità da 5" dell'altra catena e viceversa (Fig. 5.3). Tuttavia, si dovrebbero tenere presenti i dati moderni secondo cui il materiale genetico di alcuni virus è rappresentato da molecole di DNA a filamento singolo (a filamento singolo). Basandosi sui dati di diffrazione dei raggi X del DNA, J. Watson e F. Crick conclusero anche che la sua molecola a doppio filamento ha una struttura secondaria sotto forma di un'elica attorcigliata nella direzione da sinistra a destra, che in seguito fu chiamata 5 -forma (Fig. 5.4). Ad oggi è stato dimostrato che oltre alla più comune forma 5 è possibile rilevare sezioni di DNA che hanno una configurazione diversa, come destrorse (forme UN, C) e ruotato da destra a sinistra (ritorto a sinistra o a forma di Z) (Fig. 5.4). Esistono alcune differenze tra queste forme di struttura secondaria del DNA (Tabella 5.2). Ad esempio, la distanza tra due coppie adiacenti di basi azotate in un'elica a doppio filamento, espressa in nanometri (nm), è caratterizzata da valori diversi per la forma 5 e la forma Z (0,34 e 0,38 nm, rispettivamente) . Nella fig. La Figura 5.5 mostra moderni modelli tridimensionali delle forme di DNA “levigiro” e “destrogiro”.

Riso. 5.3. rappresentazione schematica della struttura primaria di un frammento di una molecola di DNA a doppio filamento: A - adenina; G - guanina; T - timina; C - citosina

Riso. 5.4.

Tabella 5.2
Proprietà delle varie forme di doppia elica del DNA
Le molecole di RNA, a seconda delle loro caratteristiche strutturali e funzionali, si dividono in diversi tipi: RNA messaggero (mRNA o mRNA), RNA ribosomiale (rRNA), RNA di trasferimento (tRNA), piccolo RNA nucleare (snRNA), ecc. Le molecole di DNA e RNA sono sempre a filamento singolo (single-stranded). Tuttavia, possono formare configurazioni più complesse (secondarie) a causa della connessione complementare delle singole sezioni di tale catena basata sull'interazione di basi azotate complementari (A-U e G-C). Ad esempio, si consideri la configurazione a quadrifoglio per la molecola di RNA di trasferimento della fenilalanina (Figura 5.6).

Riso. 5.6.
Nel 1953, D. Watson e F. Crick proposero un modello della struttura del DNA, basato sui seguenti postulati:
- 1. Il DNA è un polimero costituito da nucleotidi collegati da legami fosfodiesterici da 3" e 5".
- 2. La composizione dei nucleotidi del DNA obbedisce alle regole di Chargaff.
- 3. La molecola del DNA ha una struttura a doppia elica, che ricorda una scala a chiocciola, come evidenziato dagli schemi di diffrazione dei raggi X dei filamenti di DNA ottenuti per la prima volta da M. Wilkins e R. Franklin.
- 4. La struttura del polimero, come mostrato dalla titolazione acido-base del DNA nativo (naturale), è stabilizzata da legami idrogeno. La titolazione e il riscaldamento del DNA nativo provocano un notevole cambiamento nelle sue proprietà fisiche, in particolare nella viscosità, trasformandolo in una forma denaturata e i legami covalenti non vengono distrutti.
Gli acidi nucleici sono sostanze ad alto peso molecolare costituite da mononucleotidi, che sono collegati tra loro in una catena polimerica mediante legami fosfodiesteri da 3", 5" e sono impacchettati in un certo modo nelle cellule.
Gli acidi nucleici sono biopolimeri di due tipi: acido ribonucleico (RNA) e acido desossiribonucleico (DNA). Ogni biopolimero è costituito da nucleotidi che differiscono per il residuo carboidrato (ribosio, desossiribosio) e una delle basi azotate (uracile, timina). In base a queste differenze, gli acidi nucleici hanno ricevuto il loro nome.
Struttura dell'acido desossiribonucleico
Gli acidi nucleici hanno una struttura primaria, secondaria e terziaria.
Struttura primaria del DNA
La struttura primaria del DNA è una catena polinucleotidica lineare in cui i mononucleotidi sono collegati da legami fosfodiesterici da 3", 5". Il materiale di partenza per l'assemblaggio di una catena di acido nucleico in una cellula è il nucleoside trifosfato da 5", che, in seguito alla rimozione dei residui di acido fosforico β e γ, è in grado di attaccare l'atomo di carbonio da 3" di un altro nucleoside . Pertanto, l'atomo di carbonio da 3" di un desossiribosio è legato covalentemente all'atomo di carbonio da 5" di un altro desossiribosio attraverso un singolo residuo di acido fosforico e forma una catena polinucleotidica lineare di acido nucleico. Da qui il nome: legami fosfodiesteri da 3", 5". Le basi azotate non prendono parte al collegamento dei nucleotidi di una catena (Fig. 1.).
Tale connessione tra il residuo molecolare di acido fosforico di un nucleotide e il carboidrato di un altro porta alla formazione di uno scheletro pentoso-fosfato della molecola polinucleotidica, sulla quale sono attaccate una dopo l'altra le basi azotate. La loro sequenza di disposizione nelle catene delle molecole di acido nucleico è strettamente specifica per le cellule di diversi organismi, ad es. ha un carattere specifico (regola di Chargaff).
Una catena lineare di DNA, la cui lunghezza dipende dal numero di nucleotidi inclusi nella catena, ha due estremità: una è chiamata estremità da 3" e contiene un ossidrile libero, e l'altra è chiamata estremità da 5" e contiene un ossidrile libero. residuo acido. Il circuito è polare e può avere una direzione 5"->3" e 3"->5". L'eccezione è il DNA circolare.
Il "testo" genetico del DNA è composto da "parole" in codice: triplette di nucleotidi chiamate codoni. Sezioni di DNA contenenti informazioni sulla struttura primaria di tutti i tipi di RNA sono chiamate geni strutturali.
Le catene di DNA polinucleotidico raggiungono dimensioni gigantesche, quindi sono impacchettate in un certo modo nella cellula.
Studiando la composizione del DNA, Chargaff (1949) stabilì importanti schemi riguardanti il contenuto delle singole basi del DNA. Hanno contribuito a rivelare la struttura secondaria del DNA. Questi modelli sono chiamati regole di Chargaff. Regole di Chargaff
Queste regole indicano che nella costruzione del DNA si deve osservare una corrispondenza (accoppiamento) abbastanza stretta non delle basi puriniche e pirimidiniche in generale, ma specificamente della timina con l'adenina e della citosina con la guanina. Sulla base di queste regole, nel 1953, Watson e Crick proposero un modello della struttura secondaria del DNA, chiamato doppia elica (Fig.). |

Struttura secondaria del DNA
La struttura secondaria del DNA è una doppia elica, il cui modello fu proposto da D. Watson e F. Crick nel 1953.
Prerequisiti per la creazione di un modello di DNA
Come risultato delle analisi iniziali, si credeva che il DNA di qualsiasi origine contenesse tutti e quattro i nucleotidi in quantità molari uguali. Tuttavia, negli anni '40, E. Chargaff e i suoi colleghi, a seguito dell'analisi del DNA isolato da una varietà di organismi, dimostrarono chiaramente che contenevano basi azotate in diversi rapporti quantitativi. Chargaff scoprì che sebbene questi rapporti siano gli stessi per il DNA di tutte le cellule della stessa specie di organismo, il DNA di specie diverse può differire notevolmente nel contenuto di alcuni nucleotidi. Ciò ha suggerito che le differenze nel rapporto delle basi azotate potrebbero essere associate a qualche tipo di codice biologico. Sebbene il rapporto tra le singole basi purine e pirimidiniche nei diversi campioni di DNA si sia rivelato diverso, confrontando i risultati del test è emerso un certo schema: in tutti i campioni, il numero totale di purine era uguale al numero totale di pirimidine (A + G = T + C), la quantità di adenina era uguale alla quantità di timina (A = T) e la quantità di guanina era la quantità di citosina (G = C). Il DNA isolato da cellule di mammifero era generalmente più ricco di adenina e timina e relativamente più povero di guanina e citosina, mentre il DNA dei batteri era più ricco di guanina e citosina e relativamente più povero di adenina e timina. Questi dati costituivano una parte importante del materiale fattuale sulla base del quale fu successivamente costruito il modello Watson-Crick della struttura del DNA.
Un’altra importante indicazione indiretta sulla possibile struttura del DNA è stata fornita dai dati di L. Pauling sulla struttura delle molecole proteiche. Pauling ha dimostrato che sono possibili diverse configurazioni stabili della catena di amminoacidi in una molecola proteica. Una configurazione comune della catena peptidica, l'α-elica, è una struttura elicoidale regolare. Con questa struttura è possibile la formazione di legami idrogeno tra amminoacidi situati su spire adiacenti della catena. Pauling descrisse la configurazione α-elicoidale della catena polipeptidica nel 1950 e suggerì che le molecole di DNA probabilmente hanno una struttura elicoidale tenuta in posizione da legami idrogeno.
Tuttavia, le informazioni più preziose sulla struttura della molecola di DNA sono state fornite dai risultati dell'analisi di diffrazione dei raggi X. I raggi X che passano attraverso un cristallo di DNA subiscono diffrazione, cioè vengono deviati in determinate direzioni. Il grado e la natura della deflessione dei raggi dipendono dalla struttura delle molecole stesse. Uno schema di diffrazione dei raggi X (Fig. 3) fornisce all'occhio esperto una serie di indicazioni indirette riguardanti la struttura delle molecole della sostanza oggetto di studio. L'analisi dei modelli di diffrazione dei raggi X del DNA ha portato alla conclusione che le basi azotate (che hanno una forma piatta) sono disposte come una pila di piastre. I modelli di diffrazione dei raggi X hanno rivelato tre periodi principali nella struttura del DNA cristallino: 0,34, 2 e 3,4 nm.

Modello del DNA di Watson-Crick
Basandosi sui dati analitici di Chargaff, sui modelli di raggi X di Wilkins e sulla ricerca dei chimici che fornirono informazioni sulle distanze precise tra gli atomi in una molecola, sugli angoli tra i legami di un dato atomo e sulla dimensione degli atomi, Watson e Crick iniziò a costruire modelli fisici dei singoli componenti della molecola di DNA su una certa scala e ad "adattarli" tra loro in modo tale che il sistema risultante corrispondesse a vari dati sperimentali [spettacolo] .
Era noto anche prima che i nucleotidi vicini in una catena di DNA sono collegati da ponti fosfodiestere, che collegano l'atomo di carbonio desossiriboso da 5" di un nucleotide con l'atomo di carbonio desossiribosio da 3" del nucleotide successivo. Watson e Crick non avevano dubbi che il periodo di 0,34 nm corrisponde alla distanza tra i nucleotidi successivi nella catena del DNA. Inoltre si potrebbe supporre che il periodo di 2 nm corrisponda allo spessore della catena. E per spiegare a quale struttura reale corrisponde il periodo di 3,4 nm, Watson e Crick, così come Pauling in precedenza, hanno suggerito che la catena sia attorcigliata a forma di spirale (o, più precisamente, formi una linea elicoidale, poiché una spirale in senso stretto si ottiene quando le spire formano nello spazio una superficie conica anziché cilindrica). Quindi un periodo di 3,4 nm corrisponderà alla distanza tra le spire successive di questa elica. Una tale spirale può essere molto densa o leggermente allungata, cioè le sue svolte possono essere piatte o ripide. Poiché il periodo di 3,4 nm è esattamente 10 volte la distanza tra nucleotidi successivi (0,34 nm), è chiaro che ogni giro completo dell'elica contiene 10 nucleotidi. Da questi dati, Watson e Crick sono riusciti a calcolare la densità di una catena polinucleotidica attorcigliata ad elica con un diametro di 2 nm, con una distanza tra le spire di 3,4 nm. Si è scoperto che una catena del genere avrebbe una densità pari alla metà di quella effettiva del DNA, che era già nota. Ho dovuto presumere che la molecola del DNA sia composta da due catene: che sia una doppia elica di nucleotidi.
Il compito successivo era, ovviamente, chiarire le relazioni spaziali tra le due catene che formano la doppia elica. Dopo aver provato una serie di opzioni per la disposizione delle catene sul loro modello fisico, Watson e Crick hanno scoperto che tutti i dati disponibili corrispondevano meglio all'opzione in cui due eliche polinucleotidiche vanno in direzioni opposte; in questo caso, catene costituite da residui di zucchero e fosfato formano la superficie della doppia elica e all'interno si trovano purine e pirimidine. Le basi poste una di fronte all'altra, appartenenti a due catene, sono collegate a coppie da legami idrogeno; Sono questi legami idrogeno che tengono insieme le catene, fissando così la configurazione complessiva della molecola.
La doppia elica del DNA può essere immaginata come una scala di corda attorcigliata in modo elicoidale, in modo che i suoi pioli rimangano orizzontali. Quindi le due corde longitudinali corrisponderanno a catene di residui di zucchero e fosfato, e le traverse corrisponderanno a coppie di basi azotate collegate da legami idrogeno.
Come risultato di ulteriori studi sui possibili modelli, Watson e Crick conclusero che ciascuna "traversa" dovrebbe consistere di una purina e una pirimidina; ad un periodo di 2 nm (corrispondente al diametro della doppia elica), non ci sarebbe spazio sufficiente per due purine, e le due pirimidine non potrebbero essere abbastanza vicine tra loro per formare veri e propri legami idrogeno. Uno studio approfondito del modello dettagliato ha mostrato che l'adenina e la citosina, pur formando una combinazione di dimensioni adeguate, non potevano ancora essere posizionate in modo tale che tra loro si formassero legami idrogeno. Rapporti simili hanno costretto ad escludere la combinazione guanina - timina, mentre le combinazioni adenina - timina e guanina - citosina si sono rivelate abbastanza accettabili. La natura dei legami idrogeno è tale che l'adenina forma una coppia con la timina e la guanina con la citosina. Questa idea di accoppiamento di basi specifico ha permesso di spiegare la "regola di Chargaff", secondo la quale in qualsiasi molecola di DNA la quantità di adenina è sempre uguale al contenuto di timina, e la quantità di guanina è sempre uguale alla quantità di citosina. Si formano due legami idrogeno tra adenina e timina e tre tra guanina e citosina. A causa di questa specificità, la formazione di legami idrogeno contro ciascuna adenina in una catena provoca la formazione di timina sull'altra; allo stesso modo, solo la citosina può essere opposta a ciascuna guanina. Pertanto, le catene sono complementari tra loro, cioè la sequenza dei nucleotidi in una catena determina in modo univoco la loro sequenza nell'altra. Le due catene corrono in direzioni opposte e i loro gruppi fosfati terminali si trovano alle estremità opposte della doppia elica.
Come risultato della loro ricerca, nel 1953 Watson e Crick proposero un modello della struttura della molecola del DNA (Fig. 3), che rimane attuale fino ai giorni nostri. Secondo il modello, la molecola del DNA è costituita da due catene polinucleotidiche complementari. Ogni filamento di DNA è un polinucleotide costituito da diverse decine di migliaia di nucleotidi. In esso, i nucleotidi vicini formano uno scheletro regolare di pentoso-fosfato dovuto alla connessione di un residuo di acido fosforico e desossiribosio mediante un forte legame covalente. Le basi azotate di una catena polinucleotidica sono disposte in un ordine rigorosamente definito di fronte alle basi azotate dell'altra. L'alternanza delle basi azotate in una catena polinucleotidica è irregolare.
La disposizione delle basi azotate nella catena del DNA è complementare (dal greco "complemento" - addizione), cioè La timina (T) è sempre contro l'adenina (A) e solo la citosina (C) è contro la guanina (G). Ciò è spiegato dal fatto che A e T, così come G e C, corrispondono strettamente tra loro, cioè si completano a vicenda. Questa corrispondenza è determinata dalla struttura chimica delle basi, che consente la formazione di legami idrogeno nella coppia purina e pirimidina. Ci sono due connessioni tra A e T e tre tra G e C. Questi legami forniscono una stabilizzazione parziale della molecola di DNA nello spazio. La stabilità della doppia elica è direttamente proporzionale al numero di legami G≡C, che sono più stabili rispetto ai legami A=T.
La sequenza nota di disposizione dei nucleotidi in una catena di DNA consente, secondo il principio di complementarità, di stabilire i nucleotidi di un'altra catena.
Inoltre, è stato stabilito che le basi azotate aventi struttura aromatica in una soluzione acquosa si trovano una sopra l'altra, formando, per così dire, una pila di monete. Questo processo di formazione di pile di molecole organiche è chiamato impilamento. Le catene polinucleotidiche della molecola di DNA del modello Watson-Crick in esame hanno uno stato fisico-chimico simile, le loro basi azotate sono disposte sotto forma di una pila di monete, tra i piani di cui sorgono le interazioni di van der Waals (interazioni di impilamento).
I legami idrogeno tra basi complementari (orizzontalmente) e le interazioni di impilamento tra piani di basi in una catena polinucleotidica dovute alle forze di van der Waals (verticalmente) forniscono alla molecola di DNA un'ulteriore stabilizzazione nello spazio.
Le strutture portanti di fosfato di zucchero di entrambe le catene sono rivolte verso l'esterno e le basi sono rivolte verso l'interno, l'una verso l'altra. La direzione delle catene nel DNA è antiparallela (una di esse ha una direzione di 5"->3", l'altra - 3"->5", cioè l'estremità di 3" di una catena si trova di fronte all'estremità di 5" di l'altro.). Le catene formano spirali destrorse con un asse comune. Un giro dell'elica è di 10 nucleotidi, la dimensione del giro è 3,4 nm, l'altezza di ciascun nucleotide è 0,34 nm, il diametro dell'elica è 2,0 nm. Come risultato della rotazione di un filamento attorno ad un altro, si formano un solco maggiore (circa 20 Å di diametro) e un solco minore (circa 12 Å di diametro) della doppia elica del DNA. Questa forma della doppia elica Watson-Crick fu successivamente chiamata forma B. Nelle cellule, il DNA solitamente esiste nella forma B, che è la più stabile.
Funzioni del DNA
Il modello proposto spiega molte proprietà biologiche dell'acido desossiribonucleico, inclusa la conservazione dell'informazione genetica e la diversità dei geni fornita da un'ampia varietà di combinazioni sequenziali di 4 nucleotidi e il fatto dell'esistenza di un codice genetico, la capacità di auto-riprodursi e trasmettere le informazioni genetiche fornite dal processo di replicazione e l'implementazione delle informazioni genetiche sotto forma di proteine, nonché qualsiasi altro composto formato con l'aiuto di proteine enzimatiche.
Funzioni fondamentali del DNA.
- Il DNA è il portatore dell'informazione genetica, garantita dal fatto dell'esistenza di un codice genetico.
- Riproduzione e trasmissione dell'informazione genetica attraverso generazioni di cellule e organismi. Questa funzionalità è fornita dal processo di replica.
- Implementazione delle informazioni genetiche sotto forma di proteine, nonché di qualsiasi altro composto formato con l'aiuto di proteine enzimatiche. Questa funzione è fornita dai processi di trascrizione e traduzione.

Forme di organizzazione del DNA a doppia elica
Il DNA può formare diversi tipi di doppie eliche (Fig. 4). Attualmente sono già note sei forme (dalla A alla E e alla forma Z).
Le forme strutturali del DNA, come stabilì Rosalind Franklin, dipendono dalla saturazione della molecola dell'acido nucleico con acqua. Negli studi sulle fibre di DNA utilizzando l'analisi di diffrazione dei raggi X, è stato dimostrato che il modello di raggi X dipende radicalmente dall'umidità relativa con quale grado di saturazione d'acqua di questa fibra avviene l'esperimento. Se la fibra era sufficientemente satura di acqua, veniva ottenuta una radiografia. Una volta essiccata, appariva uno schema di raggi X completamente diverso, molto diverso dallo schema di raggi X della fibra ad alta umidità.
La molecola di DNA ad alta umidità è chiamata forma B. In condizioni fisiologiche (bassa concentrazione salina, alto grado di idratazione), il tipo strutturale dominante di DNA è la forma B (la forma principale di DNA a doppio filamento - il modello Watson-Crick). Il passo dell'elica di tale molecola è 3,4 nm. Ci sono 10 coppie complementari per turno sotto forma di pile attorcigliate di "monete" - basi azotate. Le pile sono tenute insieme da legami idrogeno tra due “monete” opposte delle pile e sono “avvolte” da due nastri di fosfodiestere attorcigliati in un’elica destrorsa. I piani delle basi azotate sono perpendicolari all'asse dell'elica. Le coppie complementari adiacenti vengono ruotate l'una rispetto all'altra di 36°. Il diametro dell'elica è 20Å, con il nucleotide purinico che occupa 12Å e il nucleotide pirimidinico 8Å.
La molecola di DNA con umidità inferiore è chiamata forma A. La forma A si forma in condizioni di idratazione meno elevata e con un contenuto più elevato di ioni Na+ o K+. Questa più ampia conformazione elicoidale destrorsa ha 11 paia di basi per giro. I piani delle basi azotate hanno una maggiore inclinazione rispetto all'asse dell'elica; sono deviati dalla normale all'asse dell'elica di 20°. Ciò implica la presenza di un vuoto interno del diametro di 5Å. La distanza tra nucleotidi adiacenti è 0,23 nm, la lunghezza della spira è 2,5 nm e il diametro dell'elica è 2,3 nm.
Inizialmente si pensava che la forma A del DNA fosse meno importante. Tuttavia, in seguito divenne chiaro che la forma A del DNA, come la forma B, ha un enorme significato biologico. L'elica RNA-DNA nel complesso modello-primer ha la forma A, così come l'elica RNA-RNA e le strutture a forcina dell'RNA (il gruppo idrossile 2' del ribosio impedisce alle molecole di RNA di formare la forma B). La forma A del DNA si trova nelle spore. È stato accertato che la forma A del DNA è 10 volte più resistente ai raggi UV rispetto alla forma B.
La forma A e la forma B sono chiamate forme canoniche del DNA.
Forma C-E anche destrimani, la loro formazione può essere osservata solo in appositi esperimenti e, a quanto pare, non esistono in vivo. La forma C del DNA ha una struttura simile al DNA B. Il numero di paia di basi per giro è 9,33, la lunghezza del giro dell'elica è 3,1 nm. Le coppie di basi sono inclinate di un angolo di 8 gradi rispetto alla posizione perpendicolare all'asse. I solchi sono di dimensioni simili ai solchi del B-DNA. In questo caso, il solco principale è leggermente meno profondo e il solco minore è più profondo. I polinucleotidi del DNA naturale e sintetico possono trasformarsi nella forma C.
| Tabella 1. Caratteristiche di alcuni tipi di strutture del DNA | |||
| Tipo a spirale | UN | B | Z |
| Passo a spirale | 0,32 nanometri | 3,38 miglia nautiche | 4,46 miglia nautiche |
| Torsione a spirale | Giusto | Giusto | Sinistra |
| Numero di coppie di basi per turno | 11 | 10 | 12 |
| Distanza tra i piani base | 0,256 nm | 0,338 nm | 0,371 nm |
| Conformazione del legame glicosidico | anti | anti | anti-C cantare |
| Conformazione dell'anello furanosico | C3"-endo | C2"-endo | C3"-endo-G C2"-endo-C |
| Larghezza della scanalatura, piccola/grande | 1,11/0,22 nm | 0,57/1,17 nm | 0,2/0,88 nm |
| Profondità della scanalatura, piccola/grande | 0,26/1,30 nm | 0,82/0,85 nm | 1,38/0,37 nm |
| Diametro spirale | 2,3 nm | 2,0 nm | 1,8 nm |
Elementi strutturali del DNA
(strutture di DNA non canoniche)
Gli elementi strutturali del DNA comprendono strutture insolite limitate da alcune sequenze speciali:
|

DNA a forma di Z fu scoperto nel 1979 studiando l'esanucleotide d(CG)3 -. È stato scoperto dal professore del MIT Alexander Rich e dai suoi colleghi. La forma Z è diventata uno degli elementi strutturali più importanti del DNA perché la sua formazione è stata osservata nelle regioni del DNA dove le purine si alternano con le pirimidine (ad esempio, 5'-GCGCGC-3'), o nelle ripetizioni 5 '-CGCGCG-3' contenente citosina metilata. Una condizione essenziale per la formazione e la stabilizzazione del Z-DNA era la presenza in esso di nucleotidi purinici nella conformazione syn, alternati con basi pirimidiniche nella conformazione anti.
Le molecole di DNA naturale esistono principalmente nella forma B destrorsa a meno che non contengano sequenze come (CG) n. Tuttavia, se tali sequenze fanno parte del DNA, allora queste sezioni, quando cambia la forza ionica della soluzione o dei cationi che neutralizzano la carica negativa sulla struttura del fosfodiestere, queste sezioni possono trasformarsi nella forma Z, mentre altre sezioni del DNA in la catena rimane nella classica forma B. La possibilità di una tale transizione indica che i due filamenti della doppia elica del DNA sono in uno stato dinamico e possono svolgersi l'uno rispetto all'altro, passando dalla forma destrorsa a quella sinistrorsa e viceversa. Le conseguenze biologiche di tale labilità, che consente trasformazioni conformazionali della struttura del DNA, non sono ancora del tutto comprese. Si ritiene che le sezioni del Z-DNA svolgano un certo ruolo nella regolazione dell'espressione di alcuni geni e prendano parte alla ricombinazione genetica.
La forma Z del DNA è una doppia elica sinistrorsa in cui la struttura fosfodiesterica è posizionata a zigzag lungo l'asse della molecola. Da qui il nome della molecola (zigzag)-DNK. Il DNA Z è il DNA meno attorcigliato (12 paia di basi per giro) e più sottile conosciuto in natura. La distanza tra nucleotidi adiacenti è 0,38 nm, la lunghezza della spira è 4,56 nm e il diametro dello Z-DNA è 1,8 nm. Inoltre, l'aspetto di questa molecola di DNA si distingue per la presenza di un unico solco.
La forma Z del DNA è stata trovata nelle cellule procariotiche ed eucariotiche. Sono stati ora ottenuti anticorpi in grado di distinguere la forma Z dalla forma B del DNA. Questi anticorpi si legano ad alcune regioni dei cromosomi giganti delle cellule delle ghiandole salivari della Drosophila (Dr. melanogaster). La reazione di legame è facile da monitorare grazie alla struttura insolita di questi cromosomi, in cui le regioni più dense (dischi) contrastano con quelle meno dense (interdischi). Le regioni Z-DNA si trovano negli interdischi. Ne consegue che la forma Z esiste effettivamente in condizioni naturali, sebbene le dimensioni delle singole sezioni della forma Z siano ancora sconosciute.

(invertitori) sono le sequenze di basi più famose e frequenti nel DNA. Un palindromo è una parola o una frase che si legge allo stesso modo da sinistra a destra e viceversa. Esempi di tali parole o frasi sono: CAPANNA, COSSACCO, FLOOD E LA ROSA CADUTA SULLA ZAMPA DI AZOR. Quando applicato alle sezioni del DNA, questo termine (palindromo) indica la stessa alternanza di nucleotidi lungo la catena da destra a sinistra e da sinistra a destra (come le lettere nella parola “capanna”, ecc.).
Un palindromo è caratterizzato dalla presenza di ripetizioni invertite di sequenze di basi che hanno simmetria di secondo ordine rispetto a due filamenti di DNA. Tali sequenze, per ovvi motivi, sono autocomplementari e tendono a formare strutture a forcina o a croce (Fig.). Le forcine aiutano le proteine regolatrici a riconoscere dove viene copiato il testo genetico del DNA cromosomico.
Quando sullo stesso filamento di DNA è presente una ripetizione invertita, la sequenza viene chiamata ripetizione speculare. Le ripetizioni dello specchio non hanno proprietà di auto-complementarità e, pertanto, non sono in grado di formare strutture a forcina o cruciformi. Sequenze di questo tipo si trovano in quasi tutte le grandi molecole di DNA e possono variare da poche paia di basi a diverse migliaia di paia di basi.
La presenza di palindromi sotto forma di strutture cruciformi nelle cellule eucariotiche non è stata dimostrata, sebbene un certo numero di strutture cruciformi sia stato rilevato in vivo nelle cellule di E. coli. La presenza di sequenze auto-complementari nell'RNA o nel DNA a filamento singolo è la ragione principale per il ripiegamento della catena dell'acido nucleico nelle soluzioni in una determinata struttura spaziale, caratterizzata dalla formazione di numerose "forcine".

DNA a forma Hè un'elica formata da tre filamenti di DNA: una tripla elica del DNA. È un complesso di doppia elica Watson-Crick con un terzo filamento di DNA a filamento singolo, che si inserisce nel suo solco principale, formando la cosiddetta coppia Hoogsteen.
La formazione di un tale triplex avviene come risultato del ripiegamento della doppia elica del DNA in modo tale che metà della sua sezione rimanga sotto forma di doppia elica e l'altra metà sia separata. In questo caso, una delle eliche disconnesse forma una nuova struttura con la prima metà della doppia elica - una tripla elica, e la seconda risulta non strutturata, sotto forma di una sezione a filamento singolo. Una caratteristica di questa transizione strutturale è la sua forte dipendenza dal pH del mezzo, i cui protoni stabilizzano la nuova struttura. A causa di questa caratteristica, la nuova struttura è stata chiamata la forma H del DNA, la cui formazione è stata scoperta in plasmidi superavvolti contenenti regioni omopurina-omopirimidina, che sono una ripetizione speculare.
In ulteriori studi, è stato stabilito che è possibile effettuare una transizione strutturale di alcuni polinucleotidi a doppio filamento omopurina-omopirimidina con la formazione di una struttura a tre filamenti contenente:
- un filamento di omopurina e due di omopirimidina ( Triplex Py-Pu-Py) [Interazione Hoogsteen].
I blocchi costitutivi del triplex Py-Pu-Py sono le triadi isomorfe canoniche CGC+ e TAT. La stabilizzazione del triplex richiede la protonazione della triade CGC+, quindi questi triplex dipendono dal pH della soluzione.
- un filamento di omopirimidina e due di omopurina ( Triplex Py-Pu-Pu) [interazione inversa di Hoogsteen].
I blocchi costitutivi del triplex Py-Pu-Pu sono le triadi isomorfe canoniche CGG e TAA. Una proprietà essenziale dei triplex Py-Pu-Pu è la dipendenza della loro stabilità dalla presenza di ioni a doppia carica, e sono necessari ioni diversi per stabilizzare i triplex di sequenze diverse. Poiché la formazione dei triplex Py-Pu-Pu non richiede la protonazione dei nucleotidi costituenti, tali triplex possono esistere a pH neutro.
Nota: le interazioni dirette e inverse di Hoogsteen sono spiegate dalla simmetria della 1-metiltimina: una rotazione di 180° fa sì che l'atomo di O2 prenda il posto dell'atomo di O4, mentre il sistema di legami idrogeno viene preservato.
Sono noti due tipi di tripla elica:
- triple eliche parallele in cui la polarità del terzo filamento coincide con la polarità della catena omopurinica del duplex Watson-Crick
- triple eliche antiparallele, in cui le polarità della terza catena e dell'omopurina sono opposte.

G-quadruplex-DNA a 4 filamenti. Questa struttura si forma se ci sono quattro guanine, che formano il cosiddetto G-quadruplex - una danza rotonda di quattro guanine.
I primi indizi sulla possibilità della formazione di tali strutture furono ricevuti molto prima del lavoro rivoluzionario di Watson e Crick, nel 1910. Poi il chimico tedesco Ivar Bang scoprì che uno dei componenti del DNA - l'acido guanosinico - forma gel ad alte concentrazioni, mentre altri componenti del DNA non hanno questa proprietà.
Nel 1962, utilizzando il metodo della diffrazione dei raggi X, fu possibile stabilire la struttura cellulare di questo gel. Risultò essere composto da quattro residui di guanina, collegati tra loro in un cerchio e formanti un caratteristico quadrato. Al centro il legame è sostenuto da uno ione metallico (Na, K, Mg). Le stesse strutture possono formarsi nel DNA se contiene molta guanina. Questi quadrati piatti (quartetti di sol) sono impilati per formare strutture abbastanza stabili e dense (quadruplex di sol).
Quattro filamenti separati di DNA possono essere intrecciati in complessi a quattro filamenti, ma questa è piuttosto un'eccezione. Più spesso, un singolo filamento di acido nucleico viene semplicemente legato in un nodo, formando ispessimenti caratteristici (ad esempio, alle estremità dei cromosomi), oppure il DNA a doppio filamento in alcune regioni ricche di guanina forma un quadruplex locale.
L'esistenza di quadruplex alle estremità dei cromosomi - nei telomeri e nei promotori del tumore - è stata quella più studiata. Tuttavia, non è ancora noto un quadro completo della localizzazione di tale DNA nei cromosomi umani.
Tutte queste insolite strutture di DNA in forma lineare sono instabili rispetto al DNA in forma B. Tuttavia, il DNA spesso esiste in una forma circolare di tensione topologica quando presenta quello che viene chiamato superavvolgimento. In queste condizioni, si formano facilmente strutture di DNA non canoniche: forme Z, “croci” e “forcine”, forme H, quadruplex di guanina e i-motivo.
- Forma superavvolta: si nota quando viene rilasciata dal nucleo cellulare senza danneggiare la struttura principale del pentoso fosfato. Ha la forma di anelli chiusi super ritorti. Nello stato superavvolto, la doppia elica del DNA viene “attorcigliata su se stessa” almeno una volta, cioè contiene almeno un supergiro (prende la forma di un otto).
- Stato rilassato del DNA - osservato con una singola rottura (rottura di un filamento). In questo caso i superavvolgimenti scompaiono e il DNA assume la forma di un anello chiuso.
- La forma lineare del DNA si osserva quando due filamenti di una doppia elica vengono rotti.
Struttura terziaria del DNA
Struttura terziaria del DNA si forma come risultato di un'ulteriore torsione nello spazio di una molecola a doppia elica: il suo superavvolgimento. Il superavvolgimento della molecola di DNA nelle cellule eucariotiche, a differenza dei procarioti, avviene sotto forma di complessi con proteine.
Quasi tutto il DNA degli eucarioti si trova nei cromosomi dei nuclei, solo una piccola quantità è contenuta nei mitocondri e nelle piante nei plastidi. La sostanza principale dei cromosomi delle cellule eucariotiche (compresi i cromosomi umani) è la cromatina, costituita da DNA a doppio filamento, proteine istoniche e non istoniche.
Proteine della cromatina istonica
Gli istoni sono proteine semplici che costituiscono fino al 50% della cromatina. In tutte le cellule animali e vegetali studiate sono state trovate cinque classi principali di istoni: H1, H2A, H2B, H3, H4, diversi per dimensione, composizione aminoacidica e carica (sempre positiva).
L'istone H1 dei mammiferi è costituito da una singola catena polipeptidica contenente circa 215 aminoacidi; le dimensioni degli altri istoni variano da 100 a 135 aminoacidi. Sono tutti spiralizzati e attorcigliati in un globulo con un diametro di circa 2,5 nm e contengono una quantità insolitamente grande di amminoacidi caricati positivamente lisina e arginina. Gli istoni possono essere acetilati, metilati, fosforilati, poli(ADP)-ribosilati e gli istoni H2A e H2B sono legati covalentemente all'ubiquitina. Il ruolo di tali modifiche nella formazione della struttura e nello svolgimento delle funzioni da parte degli istoni non è stato ancora completamente chiarito. Si presume che questa sia la loro capacità di interagire con il DNA e fornire uno dei meccanismi per regolare l'azione dei geni.
Gli istoni interagiscono con il DNA principalmente attraverso legami ionici (ponti salini) formati tra i gruppi fosfato del DNA caricati negativamente e i residui di lisina e arginina caricati positivamente degli istoni.
Proteine della cromatina non istoniche
Le proteine non istoniche, a differenza degli istoni, sono molto diverse. Sono state isolate fino a 590 diverse frazioni di proteine non istoniche che legano il DNA. Sono anche chiamate proteine acide, poiché la loro struttura è dominata da amminoacidi acidi (sono polianioni). La diversità delle proteine non istoniche è associata alla regolazione specifica dell'attività della cromatina. Ad esempio, gli enzimi necessari per la replicazione e l'espressione del DNA possono legarsi transitoriamente alla cromatina. Altre proteine, ad esempio quelle coinvolte in vari processi regolatori, si legano al DNA solo in tessuti specifici o in determinati stadi di differenziazione. Ciascuna proteina è complementare a una sequenza specifica di nucleotidi del DNA (sito del DNA). Questo gruppo include:
- famiglia di proteine zinc finger sito specifiche. Ogni “dito di zinco” riconosce un sito specifico costituito da 5 coppie di nucleotidi.
- famiglia di proteine sito specifiche - omodimeri. Il frammento di tale proteina a contatto con il DNA ha una struttura elica-giro-elica.
- le proteine del gel ad alta mobilità (proteine HMG) sono un gruppo di proteine strutturali e regolatrici costantemente associate alla cromatina. Hanno un peso molecolare inferiore a 30 kDa e sono caratterizzati da un elevato contenuto di aminoacidi carichi. A causa del loro basso peso molecolare, le proteine HMG hanno un'elevata mobilità durante l'elettroforesi su gel di poliacrilammide.
- Enzimi di replicazione, trascrizione e riparazione.
Con la partecipazione di proteine strutturali, regolatrici ed enzimi coinvolti nella sintesi di DNA e RNA, il filo del nucleosoma viene convertito in un complesso altamente condensato di proteine e DNA. La struttura risultante è 10.000 volte più corta della molecola di DNA originale.

Cromatina
La cromatina è un complesso di proteine con DNA nucleare e sostanze inorganiche. La maggior parte della cromatina è inattiva. Contiene DNA compatto e condensato. Questa è l'eterocromatina. Esistono cromatina costitutiva, geneticamente inattiva (DNA satellitare) costituita da regioni non espresse e facoltativa - inattiva in un numero di generazioni, ma in determinate circostanze capaci di esprimersi.
La cromatina attiva (eucromatina) non è condensata, cioè imballato meno strettamente. In diverse celle il suo contenuto varia dal 2 all'11%. È più abbondante nelle cellule cerebrali - 10-11%, nelle cellule epatiche - 3-4 e nelle cellule renali - 2-3%. Si nota la trascrizione attiva dell'eucromatina. Inoltre, la sua organizzazione strutturale consente di utilizzare in modo diverso la stessa informazione genetica del DNA insita in un dato tipo di organismo nelle cellule specializzate.
Al microscopio elettronico, l'immagine della cromatina ricorda le perle: ispessimenti sferici di circa 10 nm, separati da ponti filiformi. Questi ispessimenti sferici sono chiamati nucleosomi. Il nucleosoma è un'unità strutturale della cromatina. Ciascun nucleosoma contiene un segmento di DNA superavvolto da 146 bp avvolto per formare 1,75 spire sinistre per nucleo nucleosomale. Il nucleo nucleosomale è un ottamero istonico costituito dagli istoni H2A, H2B, H3 e H4, due molecole di ciascun tipo (Fig. 9), che si presenta come un disco con un diametro di 11 nm e uno spessore di 5,7 nm. Il quinto istone, H1, non fa parte del nucleo nucleosomale e non è coinvolto nel processo di avvolgimento del DNA sull'ottamero dell'istone. Entra in contatto con il DNA nei siti in cui la doppia elica entra ed esce dal nucleo nucleosomiale. Si tratta di sezioni di DNA intercore (linker), la cui lunghezza varia a seconda del tipo di cellula da 40 a 50 coppie di nucleotidi. Di conseguenza varia anche la lunghezza del frammento di DNA incluso nei nucleosomi (da 186 a 196 coppie di nucleotidi).
I nucleosomi contengono circa il 90% di DNA, il resto sono linker. Si ritiene che i nucleosomi siano frammenti di cromatina "silenziosa" e che il linker sia attivo. Tuttavia, i nucleosomi possono svolgersi e diventare lineari. I nucleosomi spiegati sono già cromatina attiva. Ciò dimostra chiaramente la dipendenza della funzione dalla struttura. Si può presumere che più cromatina è contenuta nei nucleosomi globulari, meno è attiva. Ovviamente, in cellule diverse la proporzione ineguale di cromatina a riposo è associata al numero di tali nucleosomi.
Nelle fotografie al microscopio elettronico, a seconda delle condizioni di isolamento e del grado di allungamento, la cromatina può apparire non solo come un lungo filo con ispessimenti - "perle" di nucleosomi, ma anche come una fibrilla (fibra) più corta e più densa con un diametro di 30 nm, la cui formazione si osserva durante l'interazione dell'istone H1 legato alla regione di collegamento del DNA e dell'istone H3, che porta ad un'ulteriore torsione dell'elica di sei nucleosomi per giro per formare un solenoide con un diametro di 30 nm. In questo caso, la proteina istonica può interferire con la trascrizione di numerosi geni e regolarne così l'attività.
Come risultato delle interazioni del DNA con gli istoni sopra descritte, un segmento di una doppia elica del DNA di 186 paia di basi con un diametro medio di 2 nm e una lunghezza di 57 nm viene convertito in un'elica con un diametro di 10 nm e una lunghezza di 57 nm. lunghezza di 5 nm. Quando questa elica viene successivamente compressa in una fibra con un diametro di 30 nm, il grado di condensazione aumenta di altre sei volte.
In definitiva, l'impacchettamento di un duplex di DNA con cinque istoni determina una condensazione del DNA di 50 volte. Tuttavia, anche un grado di condensazione così elevato non può spiegare la compattazione di quasi 50.000 - 100.000 volte del DNA nel cromosoma in metafase. Sfortunatamente, i dettagli dell'ulteriore impaccamento della cromatina fino al cromosoma in metafase non sono ancora noti, quindi possiamo considerare solo le caratteristiche generali di questo processo.
Livelli di compattazione del DNA nei cromosomi
Ogni molecola di DNA è impacchettata in un cromosoma separato. Le cellule diploidi umane contengono 46 cromosomi, che si trovano nel nucleo della cellula. La lunghezza totale del DNA di tutti i cromosomi di una cellula è 1,74 m, ma il diametro del nucleo in cui sono racchiusi i cromosomi è milioni di volte più piccolo. Tale imballaggio compatto del DNA nei cromosomi e nei cromosomi nel nucleo cellulare è assicurato da una varietà di proteine istoniche e non istoniche che interagiscono in una determinata sequenza con il DNA (vedi sopra). La compattazione del DNA nei cromosomi consente di ridurne le dimensioni lineari di circa 10.000 volte, approssimativamente da 5 cm a 5 micron. Esistono diversi livelli di compattazione (Fig. 10).


- La doppia elica del DNA è una molecola carica negativamente con un diametro di 2 nm e una lunghezza di diversi cm.
- livello del nucleosoma- La cromatina appare al microscopio elettronico come una catena di "perle" - nucleosomi - "su un filo". Il nucleosoma è un'unità strutturale universale che si trova sia nell'eucromatina che nell'eterocromatina, nel nucleo interfase e nei cromosomi metafase.
Il livello di compattazione nucleosomiale è assicurato da proteine speciali: gli istoni. Otto domini istonici carichi positivamente formano il nucleo del nucleosoma attorno al quale è avvolta una molecola di DNA caricata negativamente. Ciò dà un accorciamento di 7 volte, mentre il diametro aumenta da 2 a 11 nm.
- livello del solenoide
Il livello solenoidale dell'organizzazione cromosomica è caratterizzato dalla torsione del filamento nucleosomico e dalla formazione di fibrille più spesse di 20-35 nm di diametro: solenoidi o superbidi. Il passo del solenoide è di 11 nm; ci sono circa 6-10 nucleosomi per giro. L'impaccamento del solenoide è considerato più probabile dell'impaccamento del superbido, secondo il quale una fibrilla della cromatina con un diametro di 20-35 nm è una catena di granuli, o superbidi, ciascuno dei quali è costituito da otto nucleosomi. A livello del solenoide, la dimensione lineare del DNA si riduce di 6-10 volte, il diametro aumenta fino a 30 nm.
- livello del ciclo
Il livello dell'ansa è fornito da proteine leganti il DNA non istoniche site-specific che riconoscono e si legano a specifiche sequenze di DNA, formando anse di circa 30-300 kb. Il circuito garantisce l'espressione genica, ad es. il circuito non è solo una formazione strutturale, ma anche funzionale. L'accorciamento a questo livello avviene 20-30 volte. Il diametro aumenta a 300 nm. Strutture a forma di anello come "spazzole di lampada" negli ovociti di anfibi possono essere osservate nei preparati citologici. Questi anelli sembrano essere superavvolti e rappresentano domini di DNA, probabilmente corrispondenti a unità di trascrizione e replicazione della cromatina. Proteine specifiche fissano le basi delle anse e, eventualmente, alcune delle loro sezioni interne. L'organizzazione del dominio ad anello promuove il ripiegamento della cromatina nei cromosomi metafasici in strutture elicoidali di ordini superiori.
- livello di dominio
Il livello di dominio dell'organizzazione dei cromosomi non è stato studiato sufficientemente. A questo livello si nota la formazione di domini ad ansa: strutture di fili (fibrille) spesse 25-30 nm, che contengono il 60% di proteine, il 35% di DNA e il 5% di RNA, sono praticamente invisibili in tutte le fasi del ciclo cellulare con il eccezione della mitosi e sono distribuiti in modo piuttosto casuale in tutto il nucleo cellulare. Strutture a forma di anello come "spazzole di lampada" negli ovociti di anfibi possono essere osservate nei preparati citologici.
I domini ad anello sono attaccati alla base alla matrice proteica intranucleare nei cosiddetti siti di attacco incorporati, spesso indicati come sequenze MAR/SAR (MAR, dall'inglese Matrix Associated Region; SAR, dall'inglese scaffold attach regioni). - Frammenti di DNA lunghi diverse centinaia di paia di basi che sono caratterizzati da un alto contenuto (>65%) di coppie di nucleotidi A/T. Ogni dominio sembra avere un'unica origine di replicazione e funziona come un'unità superelica autonoma. Qualsiasi dominio ad anello contiene molte unità di trascrizione, il cui funzionamento è probabilmente coordinato: l'intero dominio è in uno stato attivo o inattivo.
A livello di dominio, come risultato del confezionamento sequenziale della cromatina, si verifica una diminuzione delle dimensioni lineari del DNA di circa 200 volte (700 nm).
- livello cromosomico
A livello cromosomico, la condensazione del cromosoma profase in un cromosoma metafase avviene con la compattazione dei domini dell'ansa attorno alla struttura assiale delle proteine non istoniche. Questo superavvolgimento è accompagnato dalla fosforilazione di tutte le molecole H1 nella cellula. Di conseguenza, il cromosoma in metafase può essere rappresentato come anelli di solenoidi densamente impacchettati, avvolti in una spirale stretta. Un tipico cromosoma umano può contenere fino a 2.600 anse. Lo spessore di tale struttura raggiunge 1400 nm (due cromatidi) e la molecola di DNA viene accorciata di 104 volte, cioè da DNA allungato da 5 cm a 5 µm.
Funzioni dei cromosomi
In interazione con i meccanismi extracromosomici, i cromosomi forniscono
- memorizzazione delle informazioni ereditarie
- utilizzando queste informazioni per creare e mantenere l'organizzazione cellulare
- regolamentazione della lettura delle informazioni ereditarie
- autoduplicazione del materiale genetico
- trasferimento del materiale genetico dalla cellula madre alle cellule figlie.
Esistono prove che quando una regione della cromatina viene attivata, ad es. durante la trascrizione, da esso vengono rimossi in modo reversibile prima l'istone H1 e poi l'ottetto istonico. Ciò provoca la decondensazione della cromatina, la transizione sequenziale di una fibrilla di cromatina da 30 nm in una fibrilla di cromatina da 10 nm e il suo ulteriore dispiegamento in sezioni di DNA libero, cioè perdita della struttura del nucleosoma.
Dopo la scoperta del principio dell'organizzazione molecolare di una sostanza come il DNA nel 1953, la biologia molecolare iniziò a svilupparsi. Successivamente nel processo di ricerca, gli scienziati hanno scoperto come viene ricombinato il DNA, la sua composizione e come è strutturato il nostro genoma umano.
Ogni giorno si verificano processi complessi a livello molecolare. Come è strutturata la molecola del DNA, in cosa consiste? E che ruolo svolgono le molecole di DNA in una cellula? Parliamo in dettaglio di tutti i processi che si verificano all'interno della doppia catena.
Cosa sono le informazioni ereditarie?
Allora da dove è iniziato tutto? Già nel 1868 lo trovarono nei nuclei dei batteri. E nel 1928, N. Koltsov avanzò la teoria secondo cui è nel DNA che tutte le informazioni genetiche su un organismo vivente sono crittografate. Quindi J. Watson e F. Crick trovarono un modello dell'ormai famosa elica del DNA nel 1953, per il quale ricevettero meritatamente un riconoscimento e un premio: il Premio Nobel.
Cos’è comunque il DNA? Questa sostanza è composta da 2 fili uniti, o meglio spirali. Una sezione di tale catena con determinate informazioni è chiamata gene.

Il DNA memorizza tutte le informazioni su che tipo di proteine si formeranno e in quale ordine. La macromolecola del DNA è un portatore materiale di informazioni incredibilmente voluminose, che sono registrate in una sequenza rigorosa di singoli mattoni: nucleotidi. Ci sono 4 nucleotidi in totale; si completano a vicenda chimicamente e geometricamente. Questo principio di complementazione, o complementarità, nella scienza sarà descritto più avanti. Questa regola gioca un ruolo chiave nella codifica e decodifica dell'informazione genetica.
Poiché il filamento di DNA è incredibilmente lungo, non ci sono ripetizioni in questa sequenza. Ogni creatura vivente ha il suo filamento di DNA unico.
Funzioni del DNA
Le funzioni includono la memorizzazione delle informazioni ereditarie e la loro trasmissione alla prole. Senza questa funzione, il genoma di una specie non potrebbe preservarsi e svilupparsi nel corso di migliaia di anni. Gli organismi che hanno subito gravi mutazioni genetiche hanno maggiori probabilità di non sopravvivere o di perdere la capacità di produrre prole. Così avviene la protezione naturale contro la degenerazione delle specie.

Un'altra funzione essenziale è l'implementazione delle informazioni memorizzate. Una cellula non può creare una singola proteina vitale senza le istruzioni immagazzinate in una doppia catena.
Composizione degli acidi nucleici
Ora si sa con certezza di cosa sono fatti i nucleotidi stessi, gli elementi costitutivi del DNA. Contengono 3 sostanze:
- Acido ortofosforico.
- Base azotata. Basi pirimidiniche - che hanno un solo anello. Questi includono timina e citosina. Basi puriniche, che contengono 2 anelli. Questi sono guanina e adenina.
- Saccarosio. Il DNA contiene desossiribosio, l'RNA contiene ribosio.
Il numero di nucleotidi è sempre uguale al numero di basi azotate. In laboratori speciali, il nucleotide viene scomposto e da esso viene isolata la base azotata. È così che vengono studiate le proprietà individuali di questi nucleotidi e le possibili mutazioni in essi.
Livelli di organizzazione delle informazioni ereditarie
Esistono 3 livelli di organizzazione: genetico, cromosomico e genomico. Tutte le informazioni necessarie per la sintesi di una nuova proteina sono contenute in una piccola sezione della catena: il gene. Cioè, il gene è considerato il livello più basso e più semplice di codifica delle informazioni.

I geni, a loro volta, sono assemblati nei cromosomi. Grazie a questa organizzazione del portatore del materiale ereditario, gruppi di caratteristiche si alternano secondo determinate leggi e si trasmettono da una generazione all'altra. Va notato che nel corpo esiste un numero incredibile di geni, ma l'informazione non viene persa anche quando viene ricombinata molte volte.
Esistono diversi tipi di geni:
- Secondo il loro scopo funzionale, si distinguono 2 tipi: sequenze strutturali e regolatorie;
- In base alla loro influenza sui processi che si verificano nella cellula, si distinguono: geni supervitali, letali, condizionatamente letali, nonché geni mutatori e antimutatori.
I geni sono disposti lungo il cromosoma in ordine lineare. Nei cromosomi, le informazioni non sono focalizzate in modo casuale; esiste un certo ordine. Esiste persino una mappa che mostra le posizioni, o loci, dei geni. Ad esempio, è noto che il cromosoma n. 18 crittografa i dati sul colore degli occhi di un bambino.
Cos'è un genoma? Questo è il nome dato all’intero insieme di sequenze nucleotidiche nella cellula di un organismo. Il genoma caratterizza un'intera specie, non un individuo.
Qual è il codice genetico umano?
Il fatto è che l'intero enorme potenziale dello sviluppo umano risiede già nel periodo del concepimento. Tutte le informazioni ereditarie necessarie per lo sviluppo dello zigote e la crescita del bambino dopo la nascita sono crittografate nei geni. Le sezioni del DNA sono i portatori più elementari delle informazioni ereditarie.
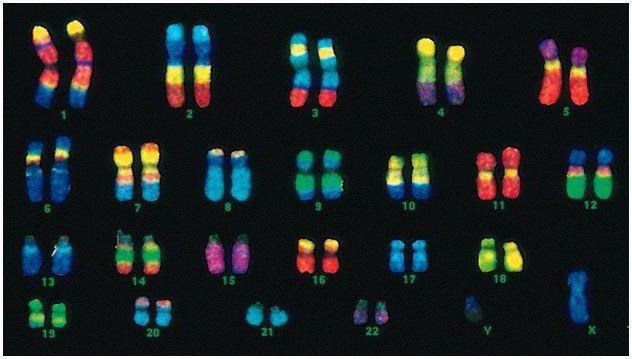
Gli esseri umani hanno 46 cromosomi, ovvero 22 coppie somatiche più un cromosoma che determina il sesso di ciascun genitore. Questo insieme diploide di cromosomi codifica l'intero aspetto fisico di una persona, le sue capacità mentali e fisiche e la suscettibilità alle malattie. I cromosomi somatici sono esteriormente indistinguibili, ma portano informazioni diverse, poiché uno di loro proviene dal padre, l'altro dalla madre.
Il codice maschile differisce dal codice femminile nell'ultima coppia di cromosomi - XY. Il set diploide femminile è l'ultima coppia, XX. I maschi ricevono un cromosoma X dalla madre biologica, che viene poi trasmesso alle figlie. Il cromosoma sessuale Y viene trasmesso ai figli maschi.
I cromosomi umani variano notevolmente in termini di dimensioni. Ad esempio, la coppia di cromosomi più piccola è la n. 17. E la coppia più grande è 1 e 3.
Il diametro della doppia elica nell'uomo è di soli 2 nm. Il DNA è avvolto così strettamente che si adatta al piccolo nucleo di una cellula, anche se sarebbe lungo fino a 2 metri se non attorcigliato. La lunghezza dell'elica è di centinaia di milioni di nucleotidi.
Come viene trasmesso il codice genetico?
Quindi, quale ruolo svolgono le molecole di DNA nella divisione cellulare? I geni, portatori di informazioni ereditarie, si trovano all'interno di ogni cellula del corpo. Per trasmettere il proprio codice a un organismo figlia, molte creature dividono il proprio DNA in 2 eliche identiche. Questa si chiama replica. Durante il processo di replicazione, il DNA si svolge e speciali “macchine” completano ogni filamento. Dopo che l'elica genetica si biforca, il nucleo e tutti gli organelli iniziano a dividersi, e quindi l'intera cellula.
Ma gli esseri umani hanno un diverso processo di trasmissione genetica: sessuale. Le caratteristiche del padre e della madre sono miste, il nuovo codice genetico contiene informazioni di entrambi i genitori.
La memorizzazione e la trasmissione delle informazioni ereditarie sono possibili grazie alla complessa organizzazione dell'elica del DNA. Dopotutto, come abbiamo detto, la struttura delle proteine è crittografata nei geni. Una volta creato al momento del concepimento, questo codice si copierà per tutta la vita. Il cariotipo (insieme personale di cromosomi) non cambia durante il rinnovamento delle cellule degli organi. Il trasferimento di informazioni viene effettuato con l'aiuto dei gameti sessuali: maschili e femminili.
Solo i virus contenenti un filamento di RNA non sono in grado di trasmettere le proprie informazioni alla prole. Pertanto, hanno bisogno di cellule umane o animali per riprodursi.
Implementazione delle informazioni ereditarie
Processi importanti si verificano costantemente nel nucleo cellulare. Tutte le informazioni registrate nei cromosomi vengono utilizzate per costruire proteine dagli aminoacidi. Ma la catena del DNA non lascia mai il nucleo, quindi ha bisogno dell'aiuto di un altro composto importante: l'RNA. È l'RNA che è in grado di penetrare nella membrana nucleare e interagire con la catena del DNA.
Attraverso l'interazione del DNA e di 3 tipi di RNA, vengono realizzate tutte le informazioni codificate. A quale livello avviene l'implementazione delle informazioni ereditarie? Tutte le interazioni avvengono a livello nucleotidico. L'RNA messaggero copia una sezione della catena del DNA e porta questa copia al ribosoma. Qui inizia la sintesi di una nuova molecola dai nucleotidi.
Affinché l'mRNA possa copiare la parte necessaria della catena, l'elica si apre e quindi, al termine del processo di ricodifica, viene ripristinata nuovamente. Inoltre, questo processo può avvenire contemporaneamente su 2 lati di 1 cromosoma.
Principio di complementarità
Sono costituiti da 4 nucleotidi: adenina (A), guanina (G), citosina (C), timina (T). Sono collegati da legami idrogeno secondo la regola della complementarità. Il lavoro di E. Chargaff ha contribuito a stabilire questa regola, poiché lo scienziato ha notato alcuni modelli nel comportamento di queste sostanze. E. Chargaff scoprì che il rapporto molare tra adenina e timina è uguale a uno. E allo stesso modo, il rapporto tra guanina e citosina è sempre uguale a uno.
Sulla base del suo lavoro, i genetisti hanno formulato una regola per l'interazione dei nucleotidi. La regola della complementarità afferma che l’adenina si combina solo con la timina e la guanina solo con la citosina. Durante la decodifica dell'elica e la sintesi di una nuova proteina nel ribosoma, questa regola di alternanza aiuta a trovare rapidamente l'amminoacido necessario che è attaccato all'RNA di trasferimento.
RNA e suoi tipi
Cosa sono le informazioni ereditarie? nucleotidi in un doppio filamento di DNA. Cos'è l'RNA? Qual è il suo lavoro? L'RNA, o acido ribonucleico, aiuta a estrarre le informazioni dal DNA, a decodificarle e, in base al principio di complementarità, a creare le proteine necessarie alle cellule.
Esistono 3 tipi di RNA in totale. Ognuno di essi svolge rigorosamente la propria funzione.
- Informativo (mRNA), o detta anche matrice. Va dritto al centro della cellula, nel nucleo. Trova in uno dei cromosomi il materiale genetico necessario per costruire una proteina e copia uno dei lati del doppio filamento. La copia avviene nuovamente secondo il principio di complementarità.
- Trasportoè una piccola molecola che ha decodificatori nucleotidici da un lato e amminoacidi corrispondenti al codice base dall'altro. Il compito del tRNA è consegnarlo al “laboratorio”, cioè al ribosoma, dove sintetizza l’amminoacido necessario.
- L'rRNA è ribosomiale. Controlla la quantità di proteine prodotte. È composto da 2 parti: una sezione amminoacidica e una sezione peptidica.
L'unica differenza nella decodifica è che l'RNA non contiene timina. Invece della timina, qui è presente l'uracile. Ma poi, durante il processo di sintesi proteica, il tRNA installa ancora correttamente tutti gli aminoacidi. Se si verificano errori nella decodifica delle informazioni, si verifica una mutazione.
Riparazione della molecola di DNA danneggiata
Il processo di ripristino di un doppio filamento danneggiato è chiamato riparazione. Durante il processo di riparazione, i geni danneggiati vengono rimossi.

Quindi la sequenza di elementi richiesta viene riprodotta esattamente e ritagliata nello stesso punto della catena da cui è stata rimossa. Tutto ciò avviene grazie a sostanze chimiche speciali: gli enzimi.
Perché si verificano le mutazioni?
Perché alcuni geni iniziano a mutare e cessano di svolgere la loro funzione, ovvero immagazzinare informazioni ereditarie vitali? Ciò si verifica a causa di un errore nella decodifica. Ad esempio, se l'adenina viene accidentalmente sostituita con la timina.
Esistono anche mutazioni cromosomiche e genomiche. Le mutazioni cromosomiche si verificano quando sezioni di informazioni ereditarie vengono perse, duplicate o addirittura trasferite e inserite in un altro cromosoma.

Le mutazioni genomiche sono le più gravi. La loro causa è un cambiamento nel numero di cromosomi. Cioè, quando invece di una coppia - un insieme diploide, nel cariotipo è presente un insieme triploide.
L'esempio più famoso di mutazione triploide è la sindrome di Down, in cui il set personale di cromosomi è 47. In questi bambini, al posto della 21a coppia si formano 3 cromosomi.
Esiste anche una mutazione nota chiamata poliploidia. Ma la poliploidia si verifica solo nelle piante.
La molecola del DNA è costituita da due filamenti che formano una doppia elica. La sua struttura fu decifrata per la prima volta da Francis Crick e James Watson nel 1953.
Inizialmente, la molecola del DNA, costituita da una coppia di catene di nucleotidi attorcigliate l'una attorno all'altra, ha dato origine a domande sul perché avesse questa forma particolare. Gli scienziati chiamano questo fenomeno complementarità, il che significa che nei suoi filamenti si possono trovare solo alcuni nucleotidi uno di fronte all'altro. Ad esempio, l'adenina è sempre opposta alla timina e la guanina è sempre opposta alla citosina. Questi nucleotidi della molecola di DNA sono chiamati complementari.
Schematicamente è rappresentato così:
T-A
C-G
Queste coppie formano un legame nucleotidico chimico, che determina l'ordine degli amminoacidi. Nel primo caso è un po’ più debole. La connessione tra C e G è più forte. I nucleotidi non complementari non formano coppie tra loro.
Riguardo l'edificio
Quindi, la struttura della molecola di DNA è speciale. Ha questa forma per un motivo: il fatto è che il numero di nucleotidi è molto grande e per ospitare lunghe catene è necessario molto spazio. È per questo motivo che le catene sono caratterizzate da una torsione a spirale. Questo fenomeno è chiamato spiralizzazione e permette ai fili di accorciarsi di circa cinque-sei volte.
L'organismo utilizza alcune molecole di questo tipo molto attivamente, altre raramente. Questi ultimi, oltre alla spiralizzazione, subiscono anche un “imballaggio compatto” come la superspiralizzazione. E poi la lunghezza della molecola di DNA diminuisce di 25-30 volte.

Qual è il “packaging” di una molecola?
Il processo di superavvolgimento coinvolge le proteine istoniche. Hanno la struttura e l'aspetto di un rocchetto di filo o di un bastoncino. Su di essi vengono avvolti dei fili spiralizzati che diventano immediatamente “impacchettati in modo compatto” e occupano poco spazio. Quando sorge la necessità di utilizzare l'uno o l'altro filo, viene svolto da una bobina, ad esempio una proteina istonica, e l'elica si svolge in due catene parallele. Quando la molecola di DNA si trova in questo stato, da essa possono essere letti i dati genetici necessari. Tuttavia, c'è una condizione. Ottenere informazioni è possibile solo se la struttura della molecola di DNA ha una forma non contorta. I cromosomi accessibili per la lettura sono chiamati eucromatine e, se sono superavvolti, sono già eterocromatine.
Acidi nucleici
Gli acidi nucleici, come le proteine, sono biopolimeri. La funzione principale è la conservazione, l'implementazione e la trasmissione delle informazioni ereditarie (informazioni genetiche). Sono disponibili in due tipi: DNA e RNA (desossiribonucleici e ribonucleici). I monomeri in essi contenuti sono nucleotidi, ciascuno dei quali contiene un residuo di acido fosforico, uno zucchero a cinque atomi di carbonio (desossiribosio/ribosio) e una base azotata. Il codice del DNA comprende 4 tipi di nucleotidi: adenina (A) / guanina (G) / citosina (C) / timina (T). Differiscono per la base azotata che contengono.
In una molecola di DNA, il numero di nucleotidi può essere enorme: da diverse migliaia a decine e centinaia di milioni. Tali molecole giganti possono essere esaminate attraverso un microscopio elettronico. In questo caso, potrai vedere una doppia catena di filamenti polinucleotidici, collegati tra loro da legami idrogeno delle basi azotate dei nucleotidi.

Ricerca
Nel corso della ricerca, gli scienziati hanno scoperto che i tipi di molecole di DNA differiscono nei diversi organismi viventi. Si è anche scoperto che la guanina di una catena può legarsi solo alla citosina e la timina all'adenina. La disposizione dei nucleotidi in una catena corrisponde strettamente a quella parallela. Grazie a questa complementarità dei polinucleotidi, la molecola del DNA è capace di raddoppiarsi e di autoriprodursi. Ma prima le catene complementari, sotto l'influenza di speciali enzimi che distruggono i nucleotidi accoppiati, divergono, e poi in ciascuna di esse inizia la sintesi della catena mancante. Ciò si verifica a causa dei nucleotidi liberi presenti in grandi quantità in ciascuna cellula. Di conseguenza, al posto della “molecola madre”, si formano due “figlie”, identiche per composizione e struttura, e il codice del DNA diventa quello originale. Questo processo è un precursore della divisione cellulare. Assicura la trasmissione di tutti i dati ereditari dalle cellule madri alle cellule figlie, nonché a tutte le generazioni successive.
Come viene letto il codice genetico?
Oggi non viene calcolata solo la massa di una molecola di DNA, ma è anche possibile scoprire dati più complessi che prima erano inaccessibili agli scienziati. Ad esempio, puoi leggere informazioni su come un organismo utilizza la propria cellula. Naturalmente, all'inizio queste informazioni sono in forma codificata e hanno la forma di una certa matrice, e quindi devono essere trasportate su un vettore speciale, che è l'RNA. L'acido ribonucleico è in grado di penetrare nella cellula attraverso la membrana nucleare e leggere le informazioni codificate al suo interno. Pertanto, l'RNA è un portatore di dati nascosti dal nucleo alla cellula e differisce dal DNA in quanto contiene ribosio invece di desossiribosio e uracile invece di timina. Inoltre, l’RNA è a filamento singolo.

Sintesi dell'RNA
Analisi approfondite del DNA hanno dimostrato che dopo che l'RNA lascia il nucleo, entra nel citoplasma, dove può essere integrato come matrice nei ribosomi (sistemi enzimatici speciali). Guidati dalle informazioni ricevute, possono sintetizzare la sequenza appropriata di aminoacidi proteici. Il ribosoma apprende dal codice tripletta quale tipo di composto organico deve essere attaccato alla catena proteica in formazione. Ogni amminoacido ha una propria tripletta specifica, che lo codifica.
Dopo che la formazione della catena è completata, acquisisce una forma spaziale specifica e si trasforma in una proteina capace di svolgere le sue funzioni ormonali, costruttive, enzimatiche e di altro tipo. Per qualsiasi organismo è un prodotto genetico. È da esso che vengono determinati tutti i tipi di qualità, proprietà e manifestazioni dei geni.

Geni
I processi di sequenziamento sono stati sviluppati principalmente per ottenere informazioni su quanti geni ha una molecola di DNA nella sua struttura. E, sebbene la ricerca abbia permesso agli scienziati di fare grandi progressi in questa materia, non è ancora possibile conoscerne il numero esatto.
Solo pochi anni fa si presumeva che le molecole di DNA contenessero circa 100mila geni. Poco dopo, la cifra scese a 80mila e nel 1998 i genetisti affermarono che in un DNA sono presenti solo 50mila geni, che rappresentano solo il 3% della lunghezza totale del DNA. Ma le ultime conclusioni dei genetisti sono state sorprendenti. Adesso sostengono che il genoma comprende 25-40mila di queste unità. Risulta che solo l'1,5% del DNA cromosomico è responsabile della codifica delle proteine.
La ricerca non si è fermata qui. Un team parallelo di specialisti di ingegneria genetica ha scoperto che il numero di geni in una molecola è esattamente 32mila. Come puoi vedere, è ancora impossibile ottenere una risposta definitiva. Ci sono troppe contraddizioni. Tutti i ricercatori fanno affidamento solo sui loro risultati.
C'è stata un'evoluzione?
Nonostante non ci siano prove dell'evoluzione della molecola (poiché la struttura della molecola del DNA è fragile e di piccole dimensioni), gli scienziati hanno comunque fatto un'ipotesi. Sulla base dei dati di laboratorio, hanno espresso la seguente versione: nella fase iniziale della sua comparsa, la molecola aveva la forma di un semplice peptide autoreplicante, che comprendeva fino a 32 amminoacidi presenti negli antichi oceani.
Dopo l'autoreplicazione, grazie alle forze della selezione naturale, le molecole hanno acquisito la capacità di proteggersi dagli elementi esterni. Cominciarono a vivere più a lungo e a riprodursi in quantità maggiori. Le molecole che si trovavano nella bolla lipidica avevano tutte le possibilità di riprodursi. Come risultato di una serie di cicli successivi, le bolle lipidiche hanno acquisito la forma di membrane cellulari e quindi di particelle ben note. Va notato che oggi qualsiasi sezione di una molecola di DNA è una struttura complessa e chiaramente funzionante, tutte le caratteristiche di cui gli scienziati non hanno ancora studiato completamente.

Mondo moderno
Recentemente, scienziati israeliani hanno sviluppato un computer in grado di eseguire trilioni di operazioni al secondo. Oggi è l’auto più veloce della Terra. L'intero segreto è che il dispositivo innovativo è alimentato dal DNA. I professori affermano che nel prossimo futuro tali computer saranno anche in grado di generare energia.
Un anno fa, gli specialisti dell'Istituto Weizmann di Rehovot (Israele) hanno annunciato la creazione di un computer molecolare programmabile costituito da molecole ed enzimi. Hanno sostituito i microchip di silicio con loro. Ad oggi il team ha fatto ulteriori progressi. Ora solo una molecola di DNA può fornire a un computer i dati necessari e il carburante necessario.
I “nanocomputer” biochimici non sono una finzione; esistono già in natura e si manifestano in ogni creatura vivente. Ma spesso non sono gestiti dalle persone. Una persona non può ancora operare sul genoma di nessuna pianta per calcolare, ad esempio, il numero “Pi”.
L’idea di utilizzare il DNA per archiviare/elaborare dati è venuta per la prima volta alla mente degli scienziati nel 1994. Fu allora che una molecola fu utilizzata per risolvere un semplice problema matematico. Da allora, numerosi gruppi di ricerca hanno proposto vari progetti relativi ai computer a DNA. Ma qui tutti i tentativi si basavano solo sulla molecola energetica. Non puoi vedere un computer del genere ad occhio nudo; sembra una soluzione trasparente di acqua in una provetta. Non contiene parti meccaniche, ma solo trilioni di dispositivi biomolecolari - e questo è solo in una goccia di liquido!
DNA umano
La gente venne a conoscenza del tipo di DNA umano nel 1953, quando gli scienziati furono in grado di dimostrare per la prima volta al mondo un modello di DNA a doppio filamento. Per questo Kirk e Watson ricevettero il Premio Nobel, poiché questa scoperta divenne fondamentale nel XX secolo.
Nel corso del tempo, ovviamente, hanno dimostrato che una molecola umana strutturata può apparire non solo come nella versione proposta. Dopo aver condotto un'analisi del DNA più dettagliata, hanno scoperto la forma A-, B- e la forma mancina Z-. La forma A- è spesso un'eccezione, poiché si forma solo in mancanza di umidità. Ma questo è possibile solo negli studi di laboratorio; per l’ambiente naturale questo è anomalo; un processo del genere non può avvenire in una cellula vivente.
La forma a B è classica ed è conosciuta come una doppia catena destrorsa, ma la forma a Z non solo è attorcigliata nella direzione opposta a sinistra, ma ha anche un aspetto più a zigzag. Gli scienziati hanno anche identificato la forma G-quadruplex. La sua struttura non ha 2, ma 4 fili. Secondo i genetisti, questa forma si verifica nelle zone in cui è presente una quantità eccessiva di guanina.

DNA artificiale
Oggi esiste già il DNA artificiale, che è una copia identica di quello reale; segue perfettamente la struttura della doppia elica naturale. Ma, a differenza del polinucleotide originale, quello artificiale ha solo due nucleotidi aggiuntivi.
Poiché il doppiaggio è stato creato sulla base di informazioni ottenute da vari studi sul DNA reale, può anche essere copiato, autoreplicandosi ed evolvendosi. Gli esperti lavorano alla creazione di una tale molecola artificiale da circa 20 anni. Il risultato è un'invenzione straordinaria in grado di utilizzare il codice genetico allo stesso modo del DNA naturale.
Alle quattro basi azotate esistenti, i genetisti ne hanno aggiunte altre due, create mediante modificazione chimica delle basi naturali. A differenza del DNA naturale, il DNA artificiale si è rivelato piuttosto corto. Contiene solo 81 paia di basi. Tuttavia, si riproduce e si evolve anche.
La replicazione di una molecola ottenuta artificialmente avviene grazie alla reazione a catena della polimerasi, ma finora ciò non avviene in modo indipendente, ma attraverso l'intervento degli scienziati. Aggiungono autonomamente gli enzimi necessari a detto DNA, ponendolo in un mezzo liquido appositamente preparato.
Risultato finale
Il processo e il risultato finale dello sviluppo del DNA possono essere influenzati da vari fattori, come le mutazioni. Ciò rende necessario studiare campioni di materia in modo che il risultato dell'analisi sia affidabile e affidabile. Un esempio è il test di paternità. Ma non possiamo fare a meno di rallegrarci del fatto che incidenti come la mutazione siano rari. Tuttavia, i campioni di materia vengono sempre ricontrollati per ottenere informazioni più precise in base all'analisi.

DNA vegetale
Grazie alle tecnologie di sequenziamento elevato (HTS) è stata fatta una rivoluzione nel campo della genomica: è possibile anche l'estrazione del DNA dalle piante. Naturalmente, ottenere DNA di peso molecolare di alta qualità da materiale vegetale pone alcune difficoltà a causa dell’elevato numero di copie del DNA dei mitocondri e dei cloroplasti, nonché dell’alto livello di polisaccaridi e composti fenolici. Per isolare la struttura che stiamo considerando in questo caso, vengono utilizzati diversi metodi.
Legame idrogeno nel DNA
Il legame idrogeno nella molecola del DNA è responsabile dell'attrazione elettromagnetica creata tra un atomo di idrogeno carico positivamente attaccato a un atomo elettronegativo. Questa interazione dipolare non soddisfa il criterio di un legame chimico. Ma può verificarsi a livello intermolecolare o in diverse parti della molecola, cioè intramolecolare.

Un atomo di idrogeno si attacca all'atomo elettronegativo che è il donatore del legame. Un atomo elettronegativo può essere azoto, fluoro o ossigeno. Attraverso la decentralizzazione, attira a sé la nuvola di elettroni dal nucleo di idrogeno e rende l'atomo di idrogeno (parzialmente) carico positivamente. Poiché la dimensione di H è piccola rispetto ad altre molecole e atomi, anche la carica è piccola.
Decodificazione del DNA
Prima di decifrare una molecola di DNA, gli scienziati prendono prima un numero enorme di cellule. Per il lavoro più accurato e di successo, ne sono necessari circa un milione. I risultati ottenuti durante lo studio vengono costantemente confrontati e registrati. Oggi la decodifica del genoma non è più una rarità, ma una procedura accessibile.

Naturalmente, decifrare il genoma di una singola cellula è un esercizio poco pratico. I dati ottenuti durante tali studi non interessano gli scienziati. Ma è importante capire che tutti i metodi di decodifica attualmente esistenti, nonostante la loro complessità, non sono sufficientemente efficaci. Consentiranno di leggere solo il 40-70% del DNA.
Tuttavia, i professori di Harvard hanno recentemente annunciato un metodo attraverso il quale è possibile decifrare il 90% del genoma. La tecnica si basa sull'aggiunta di molecole di primer alle cellule isolate, con l'aiuto delle quali inizia la replicazione del DNA. Ma anche questo metodo non può essere considerato un successo; deve ancora essere perfezionato prima di poter essere utilizzato apertamente nella scienza.
