Binomial fordeling. Diskrete distribusjoner i EXCEL. Binomialfordeling av en tilfeldig variabel Binomialfordeling utmerker seg
Tenk på binomialfordelingen, beregn dens matematiske forventning, varians, modus. Ved å bruke MS EXCEL-funksjonen BINOM.DIST(), vil vi plotte fordelingsfunksjonen og sannsynlighetstetthetsgrafene. La oss estimere fordelingsparameteren p, den matematiske forventningen til fordelingen og standardavviket. Vurder også Bernoulli-fordelingen.
Definisjon. La dem bli holdt n tester, i hver av dem kan bare 2 hendelser forekomme: hendelsen "suksess" med en sannsynlighet s eller hendelsen "feil" med sannsynligheten q =1-p (den såkalte Bernoulli-opplegg,Bernoulliprøvelser).
Sannsynlighet for å få nøyaktig x suksess i disse n tester er lik:
Antall suksesser i utvalget x er en tilfeldig variabel som har Binomial fordeling(Engelsk) Binomialfordeling) s Og n – er parametere for denne fordelingen.
Husk det for å søke Bernoulli planer og tilsvarende binomial fordeling, følgende vilkår må være oppfylt:
- hver rettssak må ha nøyaktig to utfall, betinget kalt "suksess" og "fiasko".
- Resultatet av hver test bør ikke avhenge av resultatene fra tidligere tester (testuavhengighet).
- suksess rate s bør være konstant for alle tester.
Binomialfordeling i MS EXCEL
I MS EXCEL, fra og med versjon 2010, for det er en BINOM.DIST()-funksjon, det engelske navnet er BINOM.DIST(), som lar deg beregne sannsynligheten for at prøven vil ha nøyaktig X"suksesser" (dvs. sannsynlighetstetthetsfunksjon p(x), se formel ovenfor), og integrert distribusjonsfunksjon(sannsynligheten for at utvalget vil ha x eller mindre "suksesser", inkludert 0).
Før MS EXCEL 2010 hadde EXCEL funksjonen BINOMDIST() som også lar deg beregne distribusjonsfunksjon Og sannsynlighetstetthet p(x). BINOMDIST() er igjen i MS EXCEL 2010 for kompatibilitet.
Eksempelfilen inneholder grafer sannsynlighetsfordelingstetthet Og .

Binomial fordeling har betegnelsen B (n ; s) .
Merk: For bygging integrert distribusjonsfunksjon perfekt passform diagramtype Rute, For distribusjonstetthet – Histogram med gruppering. For mer informasjon om å bygge diagrammer, les artikkelen Hovedtyper av diagrammer.
Merk: For å gjøre det enklere å skrive formler i eksempelfilen, er det opprettet navn for parametere Binomial fordeling: n og s.

Eksempelfilen viser ulike sannsynlighetsberegninger ved bruk av MS EXCEL-funksjoner:

Som vist på bildet ovenfor, antas det at:
- Den uendelige populasjonen som utvalget er laget av inneholder 10 % (eller 0,1) gode elementer (parameter s, tredje funksjonsargument = BINOM.DIST() )
- For å beregne sannsynligheten for at i et utvalg av 10 elementer (parameter n, det andre argumentet til funksjonen) vil det være nøyaktig 5 gyldige elementer (det første argumentet), du må skrive formelen: =BINOM.FORDELING(5; 10; 0.1; FALSE)
- Det siste, fjerde elementet er satt = FALSE, dvs. funksjonsverdien returneres distribusjonstetthet .
Hvis verdien til det fjerde argumentet = TRUE, returnerer funksjonen BINOM.DIST() verdien integrert distribusjonsfunksjon eller rett og slett distribusjonsfunksjon. I dette tilfellet kan du beregne sannsynligheten for at antall gode varer i utvalget vil være fra et bestemt område, for eksempel 2 eller mindre (inkludert 0).
For å gjøre dette, skriv formelen: = BINOM.FORDELING(2; 10; 0.1; SANN)
Merk: For en ikke-heltallsverdi av x, . For eksempel vil følgende formler returnere samme verdi: =BINOM.FORDELING( 2 ; 10; 0,1; EKTE)=BINOM.FORDELING( 2,9 ; 10; 0,1; EKTE)
Merk: I eksempelfilen sannsynlighetstetthet Og distribusjonsfunksjon også beregnet ved hjelp av definisjonen og COMBIN()-funksjonen.
Distribusjonsindikatorer
I eksempelfil på ark Eksempel det er formler for å beregne noen distribusjonsindikatorer:
- =n*p;
- (kvadratstandardavvik) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
Vi utleder formelen matematisk forventningBinomial fordeling ved hjelp av Bernoulli-opplegg .
Per definisjon er en tilfeldig variabel X in Bernoulli-opplegg(Bernoulli tilfeldig variabel) har distribusjonsfunksjon :

Denne fordelingen kalles Bernoulli distribusjon .
Merk : Bernoulli distribusjon- spesielt tilfelle Binomial fordeling med parameter n=1.
La oss generere 3 arrays med 100 tall med forskjellige sannsynligheter for suksess: 0,1; 0,5 og 0,9. For å gjøre dette, i vinduet Generering av tilfeldig tall angi følgende parametere for hver sannsynlighet p:

Merk: Hvis du angir alternativet Tilfeldig spredning (Tilfeldig frø), så kan du velge et bestemt tilfeldig sett med genererte tall. For eksempel, ved å sette dette alternativet =25, kan du generere de samme settene med tilfeldige tall på forskjellige datamaskiner (hvis, selvfølgelig, andre distribusjonsparametere er de samme). Opsjonsverdien kan ha heltallsverdier fra 1 til 32 767. Alternativnavn Tilfeldig spredning kan forvirre. Det ville være bedre å oversette det som Sett nummer med tilfeldige tall .
Som et resultat vil vi ha 3 kolonner med 100 tall, basert på hvilke vi for eksempel kan estimere sannsynligheten for suksess s i henhold til formelen: Antall suksesser/100(cm. eksempel filark Genererer Bernoulli).

Merk: For Bernoulli distribusjoner med p=0,5 kan du bruke formelen =RANDBETWEEN(0;1) , som tilsvarer .
Generering av tilfeldig tall. Binomial fordeling
Anta at det er 7 defekte varer i prøven. Det betyr at det er «svært sannsynlig» at andelen defekte produkter har endret seg. s, som er et kjennetegn ved vår produksjonsprosess. Selv om denne situasjonen er "svært sannsynlig", er det en mulighet (alfarisiko, type 1 feil, "falsk alarm") s forble uendret, og det økte antallet defekte produkter skyldtes stikkprøver.
Som du kan se i figuren nedenfor, er 7 antallet defekte produkter som er akseptabelt for en prosess med p=0,21 ved samme verdi Alfa. Dette illustrerer at når terskelen for defekte varer i en prøve overskrides, s"sannsynligvis" økte. Uttrykket "mest sannsynlig" betyr at det kun er 10 % sjanse (100 %-90 %) for at avviket i prosentandelen av defekte produkter over terskelen kun skyldes tilfeldige årsaker.
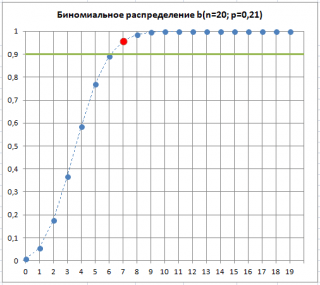
Dermed kan overskridelse av terskelantallet for defekte produkter i prøven tjene som et signal om at prosessen har blitt opprørt og begynte å produsere b O høyere prosentandel av defekte produkter.
Merk: Før MS EXCEL 2010 hadde EXCEL en funksjon CRITBINOM() , som tilsvarer BINOM.INV() . CRITBINOM() er igjen i MS EXCEL 2010 og høyere for kompatibilitet.
Forholdet mellom binomialfordelingen og andre distribusjoner
Hvis parameteren nBinomial fordeling har en tendens til uendelig og s har en tendens til 0, så i dette tilfellet Binomial fordeling kan tilnærmes. Det er mulig å formulere betingelser når tilnærmingen Giftfordeling fungerer bra:
- s(jo mindre s og mer n, jo mer nøyaktig tilnærmingen er);
- s >0,9 (vurderer q =1- s, beregninger i dette tilfellet må utføres ved hjelp av q(EN X må erstattes med n - x). Derfor, jo mindre q og mer n, jo mer nøyaktig tilnærmingen er).
På 0,110 Binomial fordeling kan tilnærmes.
I sin tur, Binomial fordeling kan tjene som en god tilnærming når populasjonsstørrelsen er N Hypergeometrisk fordeling mye større enn utvalgsstørrelsen n (dvs. N>>n eller n/N Du kan lese mer om sammenhengen mellom de ovennevnte fordelingene i artikkelen. Eksempler på tilnærming er også gitt der, og forhold er forklart når det er mulig og med hvilken nøyaktighet.
RÅD: Du kan lese om andre distribusjoner av MS EXCEL i artikkelen .
Binomialfordelingen er en av de viktigste sannsynlighetsfordelingene for diskret endring tilfeldig variabel. Binomialfordelingen er sannsynlighetsfordelingen til et tall m begivenhet EN V n gjensidig uavhengige observasjoner. Ofte en begivenhet EN kalt "suksess" av observasjon, og den motsatte hendelsen - "feil", men denne betegnelsen er veldig betinget.
Vilkår for binomialfordelingen:
- gjennomført totalt n forsøk der arrangementet EN kan forekomme eller ikke;
- begivenhet EN i hver av forsøkene kan forekomme med samme sannsynlighet s;
- testene er gjensidig uavhengige.
Sannsynligheten for at i n testhendelse EN nøyaktig m ganger, kan beregnes ved å bruke Bernoulli-formelen:
![]()
Hvor s- sannsynligheten for at hendelsen inntreffer EN;
q = 1 - s er sannsynligheten for at den motsatte hendelsen inntreffer.
La oss finne ut av det hvorfor binomialfordelingen er relatert til Bernoulli-formelen på måten beskrevet ovenfor . Arrangement - antall suksesser kl n tester er delt inn i en rekke alternativer, i hver av dem oppnås suksess i m prøvelser og fiasko - i n - m tester. Vurder ett av disse alternativene - B1 . I henhold til regelen for addisjon av sannsynligheter multipliserer vi sannsynlighetene for motsatte hendelser:
![]() ,
,
og hvis vi betegner q = 1 - s, Det
![]() .
.
Den samme sannsynligheten vil ha et annet alternativ der m suksess og n - m feil. Antall slike alternativer er lik antall måter det er mulig fra n test få m suksess.
Summen av sannsynlighetene for alle m hendelsesnummer EN(tall fra 0 til n) er lik én:

hvor hvert ledd er et ledd i Newton-binomialet. Derfor kalles den betraktede fordelingen binomialfordelingen.
I praksis er det ofte nødvendig å regne ut sannsynligheter «på det meste m suksess i n tester" eller "minst m suksess i n tester". For dette brukes følgende formler.
Integralfunksjonen, altså sannsynlighet F(m) det i n observasjonshendelse EN kommer ikke mer m en gang, kan beregnes ved hjelp av formelen:
I sin tur sannsynlighet F(≥m) det i n observasjonshendelse EN kom i det minste m en gang, beregnes med formelen:
Noen ganger er det mer praktisk å beregne sannsynligheten for at i n observasjonshendelse EN kommer ikke mer m ganger, gjennom sannsynligheten for den motsatte hendelsen:
![]() .
.
Hvilken av formlene som skal brukes avhenger av hvilken av dem som inneholder færre termer.
Egenskapene til binomialfordelingen beregnes ved å bruke følgende formler .
Forventet verdi: .
spredning: .
Standardavvik: .
Binomialfordeling og beregninger i MS Excel
Binomial distribusjonssannsynlighet P n ( m) og verdien av integralfunksjonen F(m) kan beregnes ved hjelp av MS Excel-funksjonen BINOM.DIST. Vinduet for den tilsvarende beregningen vises nedenfor (klikk på venstre museknapp for å forstørre).

MS Excel krever at du oppgir følgende data:
- antall suksesser;
- antall tester;
- sannsynlighet for suksess;
- integral - logisk verdi: 0 - hvis du trenger å regne ut sannsynligheten P n ( m) og 1 - hvis sannsynligheten F(m).
Eksempel 1 Lederen for selskapet oppsummerte informasjon om antall solgte kameraer de siste 100 dagene. Tabellen oppsummerer informasjonen og beregnet sannsynlighetene for at et visst antall kameraer vil bli solgt per dag.
Dagen avsluttes med overskudd dersom det selges 13 eller flere kameraer. Sannsynligheten for at dagen blir regnet ut med overskudd:
![]()
Sannsynligheten for at dagen vil bli utført uten fortjeneste:
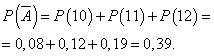
La sannsynligheten for at dagen regnes ut med overskudd være konstant og lik 0,61, og antall solgte kameraer per dag er ikke avhengig av dagen. Deretter kan du bruke binomialfordelingen, hvor hendelsen EN- dagen skal jobbes opp med overskudd, - uten overskudd.
Sannsynligheten for at alle av 6 dager vil bli utarbeidet med fortjeneste:
![]() .
.
Vi får det samme resultatet ved å bruke MS Excel-funksjonen BINOM.DIST (verdien av integralverdien er 0):
P 6 (6 ) = BINOM.FORDELING(6; 6; 0,61; 0) = 0,052.
Sannsynligheten for at 4 eller flere dager av 6 dager vil bli arbeidet med overskudd:
Hvor ![]() ,
,
![]() ,
,
Ved å bruke MS Excel-funksjonen BINOM.DIST beregner vi sannsynligheten for at av 6 dager ikke mer enn 3 dager vil bli fullført med overskudd (verdien av integralverdien er 1):
P 6 (≤3 ) = BINOM.FORDELING(3; 6; 0.61; 1) = 0.435.
Sannsynligheten for at alle av 6 dager vil bli regnet ut med tap:
![]() ,
,
Vi beregner den samme indikatoren ved å bruke MS Excel-funksjonen BINOM.DIST:
P 6 (0 ) = BINOM.FORDELING(0; 6; 0,61; 0) = 0,0035.
Løs problemet selv og se deretter løsningen
Eksempel 2 En urne inneholder 2 hvite kuler og 3 sorte. En ball tas ut av urnen, fargen settes og settes tilbake. Forsøket gjentas 5 ganger. Antall opptredener av hvite kuler er en diskret tilfeldig variabel X, fordelt i henhold til binomialloven. Lag fordelingsloven for en tilfeldig variabel. Bestem modus, matematisk forventning og varians.
Vi fortsetter å løse problemer sammen
Eksempel 3 Fra budtjenesten gikk til gjenstandene n= 5 bud. Hver kurer med en sannsynlighet s= 0,3 er sent for objektet uavhengig av de andre. Diskret tilfeldig variabel X- antall sene kurerer. Konstruer en distribusjonsserie av denne tilfeldige variabelen. Finn dens matematiske forventning, varians, standardavvik. Finn sannsynligheten for at minst to kurerer kommer for sent til gjenstandene.
I denne og de neste notatene vil vi vurdere matematiske modeller av tilfeldige hendelser. Matematisk modell er et matematisk uttrykk som representerer en tilfeldig variabel. For diskrete tilfeldige variabler er dette matematiske uttrykket kjent som distribusjonsfunksjonen.
Hvis problemet tillater deg å eksplisitt skrive et matematisk uttrykk som representerer en tilfeldig variabel, kan du beregne den nøyaktige sannsynligheten for hvilken som helst av verdiene. I dette tilfellet kan du beregne og liste alle verdiene til distribusjonsfunksjonen. I forretningsmessige, sosiologiske og medisinske applikasjoner er det ulike fordelinger av tilfeldige variabler. En av de mest nyttige distribusjonene er binomialet.
Binomial fordeling brukes til å modellere situasjoner preget av følgende funksjoner.
- Prøven består av et fast antall elementer n som representerer resultatet av en test.
- Hvert prøveelement tilhører en av to gjensidig utelukkende kategorier som dekker hele prøverommet. Vanligvis kalles disse to kategoriene suksess og fiasko.
- Sannsynlighet for suksess R er konstant. Derfor er sannsynligheten for feil 1 - s.
- Utfallet (dvs. suksess eller fiasko) av en prøve er uavhengig av utfallet av en annen prøve. For å sikre uavhengighet av utfall, innhentes prøveelementer vanligvis ved hjelp av to forskjellige metoder. Hvert utvalgselement trekkes tilfeldig fra en uendelig populasjon uten erstatning eller fra en endelig populasjon med erstatning.
Last ned notat i eller format, eksempler i format
Binomialfordelingen brukes til å estimere antall suksesser i et utvalg bestående av n observasjoner. La oss ta bestilling som et eksempel. Saxon Company-kunder kan bruke et interaktivt elektronisk skjema for å legge inn en bestilling og sende den til selskapet. Deretter sjekker informasjonssystemet om det er feil i bestillingene, samt ufullstendige eller unøyaktige opplysninger. Enhver bestilling i tvil er flagget og inkludert i den daglige unntaksrapporten. Dataene samlet inn av selskapet indikerer at sannsynligheten for feil i bestillinger er 0,1. Bedriften vil gjerne vite hva som er sannsynligheten for å finne et visst antall feilbestillinger i et gitt utvalg. Anta for eksempel at kundene har fullført fire elektroniske skjemaer. Hva er sannsynligheten for at alle bestillinger vil være feilfrie? Hvordan beregne denne sannsynligheten? Med suksess mener vi en feil ved utfylling av skjemaet, og vi vil vurdere alle andre utfall som feil. Husk at vi er interessert i antall feilbestillinger i en gitt prøve.
Hvilke utfall kan vi observere? Hvis prøven består av fire bestillinger, kan en, to, tre eller alle fire være feil, i tillegg kan alle være riktig fylt. Kan den tilfeldige variabelen som beskriver antall feil utfylte skjemaer få en annen verdi? Dette er ikke mulig fordi antall feilutfylte skjemaer ikke kan overstige prøvestørrelsen n eller være negativ. Dermed tar en tilfeldig variabel som følger den binomiale distribusjonsloven verdier fra 0 til n.
Anta at i et utvalg på fire bestillinger, observeres følgende utfall:
Hva er sannsynligheten for å finne tre feilbestillinger i et utvalg på fire bestillinger, og i den angitte rekkefølgen? Siden foreløpige studier har vist at sannsynligheten for en feil ved å fylle ut skjemaet er 0,10, beregnes sannsynlighetene for de ovennevnte utfallene som følger:
Siden utfallene er uavhengige av hverandre, er sannsynligheten for den angitte rekkefølgen av utfall lik: p*p*(1–p)*p = 0,1*0,1*0,9*0,1 = 0,0009. Hvis det er nødvendig å beregne antall valg X n elementer, bør du bruke kombinasjonsformelen (1):

hvor n! \u003d n * (n -1) * (n - 2) * ... * 2 * 1 - faktor for tallet n, og 0! = 1 og 1! = 1 per definisjon.
Dette uttrykket blir ofte referert til som . Således, hvis n = 4 og X = 3, er antallet sekvenser som består av tre elementer ekstrahert fra en prøve med størrelse 4 gitt av følgende formel:
Derfor beregnes sannsynligheten for å finne tre feilaktige ordrer som følger:
(antall mulige sekvenser) *
(sannsynlighet for en bestemt sekvens) = 4 * 0,0009 = 0,0036
På samme måte kan vi beregne sannsynligheten for at blant fire ordrer er en eller to feil, samt sannsynligheten for at alle ordrer er feil eller alle er riktige. Men etter hvert som utvalgsstørrelsen øker n det blir vanskeligere å bestemme sannsynligheten for en bestemt sekvens av utfall. I dette tilfellet bør en passende matematisk modell brukes som beskriver binomialfordelingen av antall valg X gjenstander fra en prøve som inneholder n elementer.
Binomial fordeling

Hvor P(X)- sannsynlighet X suksess for en gitt prøvestørrelse n og sannsynlighet for suksess R, X = 0, 1, … n.
Vær oppmerksom på at formel (2) er en formalisering av intuitive konklusjoner. Tilfeldig verdi X, som adlyder binomialfordelingen, kan ta en hvilken som helst heltallsverdi i området fra 0 til n. Arbeid RX(1 - p)n – X er sannsynligheten for at en bestemt sekvens består av X suksesser i utvalget, hvis størrelse er lik n. Verdien bestemmer antall mulige kombinasjoner som består av X suksess i n tester. Derfor, for et gitt antall forsøk n og sannsynlighet for suksess R sannsynligheten for en sekvens som består av X suksess er lik
P(X) = (antall mulige sekvenser) * (sannsynlighet for en bestemt sekvens) = 
Tenk på eksempler som illustrerer anvendelsen av formel (2).
1. La oss anta at sannsynligheten for å fylle ut skjemaet feil er 0,1. Hva er sannsynligheten for at tre av de fire utfylte skjemaene blir feil? Ved å bruke formel (2) får vi at sannsynligheten for å finne tre feilordre i et utvalg på fire ordrer er lik
2. Anta at sannsynligheten for feilutfylling av skjemaet er 0,1. Hva er sannsynligheten for at minst tre av fire utfylte skjema blir feil? Som vist i forrige eksempel, er sannsynligheten for at tre av de fire utfylte skjemaene blir feil 0,0036. For å beregne sannsynligheten for at minst tre av de fire utfylte skjemaene blir feil utfylt, må du legge til sannsynligheten for at blant de fire utfylte skjemaene vil tre være feil, og sannsynligheten for at alle de fire utfylte skjemaene vil være feil. Sannsynligheten for den andre hendelsen er
Dermed er sannsynligheten for at minst tre av de fire utfylte skjemaene vil være feil lik
P(X > 3) = P(X = 3) + P(X = 4) = 0,0036 + 0,0001 = 0,0037
3. Anta at sannsynligheten for feil utfylling av skjemaet er 0,1. Hva er sannsynligheten for at mindre enn tre av fire utfylte skjemaer blir feil? Sannsynligheten for denne hendelsen
P(X< 3) = P(X = 0) + P(X = 1) + P(X = 2)
Ved å bruke formel (2) beregner vi hver av disse sannsynlighetene:

Derfor P(X< 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Sannsynlighet P(X< 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х>3. Deretter P(X< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
Ettersom prøvestørrelsen øker n beregninger som ligner de som ble utført i eksempel 3 blir vanskelige. For å unngå disse komplikasjonene, er mange binomiale sannsynligheter tabellert på forhånd. Noen av disse sannsynlighetene er vist i fig. 1. For eksempel for å få sannsynligheten for at X= 2 kl n= 4 og s= 0,1, bør du trekke ut tallet i skjæringspunktet mellom linjen fra tabellen X= 2 og kolonner R = 0,1.

Ris. 1. Binomial sannsynlighet kl n = 4, X= 2 og R = 0,1
Binomialfordelingen kan beregnes ved hjelp av Excel-funksjonen =BINOM.DIST() (fig. 2), som har 4 parametere: antall suksesser - X, antall forsøk (eller prøvestørrelse) – n, er sannsynligheten for suksess R, parameter integrert, som tar verdiene TRUE (i dette tilfellet beregnes sannsynligheten i det minste X hendelser) eller FALSE (i dette tilfellet sannsynligheten for nøyaktig X arrangementer).

Ris. 2. Funksjonsparametere =BINOM.DIST()
For de tre eksemplene ovenfor er beregningene vist i fig. 3 (se også Excel-fil). Hver kolonne inneholder én formel. Tallene viser svarene på eksemplene på det tilsvarende tallet).

Ris. 3. Beregning av binomialfordeling i Excel for n= 4 og s = 0,1
Egenskaper til binomialfordelingen
Binomialfordelingen avhenger av parameterne n Og R. Binomialfordelingen kan enten være symmetrisk eller asymmetrisk. Hvis p = 0,05, er binomialfordelingen symmetrisk uavhengig av parameterverdien n. Imidlertid, hvis p ≠ 0,05, blir fordelingen skjev. Jo nærmere parameterverdien R til 0,05 og jo større prøvestørrelsen er n, jo svakere er asymmetrien til fordelingen. Dermed forskyves fordelingen av antall feilutfylte skjemaer til høyre, siden s= 0,1 (fig. 4).

Ris. 4. Histogram over binomialfordelingen for n= 4 og s = 0,1
Matematisk forventning til binomialfordelingen er lik produktet av prøvestørrelsen n på sannsynligheten for suksess R:
(3) M = E(X) =np
I gjennomsnitt, med en tilstrekkelig lang serie med tester i en prøve på fire bestillinger, kan det være p \u003d E (X) \u003d 4 x 0,1 \u003d 0,4 feil utfylte skjemaer.
Binomialfordeling standardavvik
For eksempel er standardavviket for antall feil utfylte skjemaer i et regnskapsinformasjonssystem:
Materiale fra boken Levin mfl. Statistikk for ledere benyttes. - M.: Williams, 2004. - s. 307–313
Sannsynsteorien er usynlig tilstede i livene våre. Vi legger ikke merke til det, men hver hendelse i livet vårt har en eller annen sannsynlighet. Gitt det store antallet mulige scenarier, blir det nødvendig for oss å bestemme de mest sannsynlige og minst sannsynlige av dem. Det er mest praktisk å analysere slike sannsynlighetsdata grafisk. Distribusjon kan hjelpe oss med dette. Binomial er en av de enkleste og mest nøyaktige.
Før vi går direkte videre til matematikk og sannsynlighetsteori, la oss finne ut hvem som var den første som kom opp med denne typen distribusjon, og hva er historien om utviklingen av det matematiske apparatet for dette konseptet.
Historie
Begrepet sannsynlighet har vært kjent siden antikken. Men gamle matematikere la ikke stor vekt på det og var bare i stand til å legge grunnlaget for en teori som senere ble sannsynlighetsteorien. De skapte noen kombinatoriske metoder som i stor grad hjalp de som senere skapte og utviklet selve teorien.
I andre halvdel av det syttende århundre begynte dannelsen av de grunnleggende konseptene og metodene for sannsynlighetsteori. Definisjoner av tilfeldige variabler, metoder for å beregne sannsynligheten for enkle og noen komplekse uavhengige og avhengige hendelser ble introdusert. En slik interesse for tilfeldige variabler og sannsynligheter ble diktert av gambling: hver person ønsket å vite hva sjansene hans for å vinne spillet var.
Det neste trinnet var bruken av metoder for matematisk analyse i sannsynlighetsteori. Fremstående matematikere som Laplace, Gauss, Poisson og Bernoulli tok opp denne oppgaven. Det var de som avanserte dette området av matematikk til et nytt nivå. Det var James Bernoulli som oppdaget loven om binomialfordeling. Forresten, som vi senere vil finne ut, på grunnlag av denne oppdagelsen, ble det gjort flere, som gjorde det mulig å lage loven om normalfordeling og mange andre.
Nå, før vi begynner å beskrive binomialfordelingen, skal vi friske opp litt i minnet om begrepene sannsynlighetsteori, sannsynligvis allerede glemt fra skolebenken.
Grunnleggende om sannsynlighetsteori
Vi vil vurdere slike systemer, som et resultat av at bare to utfall er mulig: "suksess" og "fiasko". Dette er lett å forstå med et eksempel: vi kaster en mynt og gjetter at haler vil falle ut. Sannsynligheten for hver av de mulige hendelsene (haler faller - "suksess", hoder faller - "ikke suksess") er lik 50 prosent hvis mynten er perfekt balansert og det ikke er andre faktorer som kan påvirke eksperimentet.
Det var den enkleste hendelsen. Men det er også komplekse systemer der sekvensielle handlinger utføres, og sannsynlighetene for utfallet av disse handlingene vil variere. Tenk for eksempel på følgende system: i en boks hvis innhold vi ikke kan se, er det seks helt identiske kuler, tre par blå, røde og hvite farger. Vi må få noen baller tilfeldig. Følgelig, ved å trekke ut en av de hvite kulene først, vil vi redusere sannsynligheten med flere ganger for at den neste også får en hvit kule. Dette skjer fordi antall objekter i systemet endres.
I neste avsnitt vil vi se på mer komplekse matematiske begreper som bringer oss nær det ordene " normal distribusjon"," binomial distribusjon "og lignende.

Elementer i matematisk statistikk
I statistikk, som er et av anvendelsesområdene til sannsynlighetsteorien, er det mange eksempler hvor data for analyse ikke er gitt eksplisitt. Det vil si ikke i tall, men i form av inndeling etter kjennetegn, for eksempel etter kjønn. For å bruke et matematisk apparat på slike data og trekke noen konklusjoner fra de oppnådde resultatene, er det nødvendig å konvertere de første dataene til et numerisk format. Som regel, for å implementere dette, tildeles et positivt utfall verdien 1, og et negativt tildeles verdien 0. Dermed får vi statistiske data som kan analyseres ved hjelp av matematiske metoder.
Det neste trinnet i å forstå hva den binomiale fordelingen av en tilfeldig variabel er, er å bestemme variansen til den tilfeldige variabelen og den matematiske forventningen. Vi skal snakke om dette i neste avsnitt.

Forventet verdi
Det er faktisk ikke vanskelig å forstå hva matematisk forventning er. Tenk på et system der det er mange forskjellige hendelser med sine egne forskjellige sannsynligheter. Den matematiske forventningen vil bli kalt verdien, lik summen produktene av verdiene til disse hendelsene (i den matematiske formen vi snakket om i den siste delen) og sannsynligheten for at de inntreffer.
Den matematiske forventningen til binomialfordelingen beregnes i henhold til samme skjema: vi tar verdien av en tilfeldig variabel, multipliserer den med sannsynligheten for et positivt utfall, og oppsummerer deretter de oppnådde dataene for alle variabler. Det er veldig praktisk å presentere disse dataene grafisk - på denne måten blir forskjellen mellom de matematiske forventningene til forskjellige verdier bedre oppfattet.
I neste avsnitt skal vi fortelle deg litt om et annet konsept – variansen til en tilfeldig variabel. Det er også nært knyttet til et slikt konsept som den binomiale sannsynlighetsfordelingen, og er dens karakteristikk.

Binomial distribusjonsvarians
Denne verdien er nært knyttet til den forrige og karakteriserer også fordelingen av statistiske data. Den representerer middelkvadraten av avvik av verdier fra deres matematiske forventninger. Det vil si at variansen til en tilfeldig variabel er summen av de kvadrerte forskjellene mellom verdien av den tilfeldige variabelen og dens matematisk forventning multiplisert med sannsynligheten for denne hendelsen.
Generelt er dette alt vi trenger å vite om varians for å forstå hva den binomiale sannsynlighetsfordelingen er. La oss nå gå videre til hovedemnet vårt. Nemlig hva som ligger bak en så tilsynelatende ganske komplisert frase «binomial distribusjonslov».

Binomial fordeling
La oss først forstå hvorfor denne fordelingen er binomial. Det kommer fra ordet "binom". Du har kanskje hørt om Newtons binomiale - en formel som kan brukes til å utvide summen av alle to tall a og b til en hvilken som helst ikke-negativ potens av n.
Som du sikkert allerede har gjettet, er Newtons binomiale formel og binomialfordelingsformelen nesten de samme formlene. Med det eneste unntaket at den andre har en anvendt verdi for spesifikke mengder, og den første er bare et generelt matematisk verktøy, hvis anvendelser i praksis kan være forskjellige.
Distribusjonsformler
Binomialfordelingsfunksjonen kan skrives som summen av følgende ledd:
(n!/(n-k)!k!)*p k *q n-k
Her er n antall uavhengige tilfeldige eksperimenter, p er antall vellykkede utfall, q er antall mislykkede utfall, k er antallet av eksperimentet (det kan ta verdier fra 0 til n),! - betegnelse på en faktorial, en slik funksjon av et tall, hvis verdi er lik produktet av alle tallene som går opp til det (for eksempel for tallet 4: 4!=1*2*3*4= 24).
I tillegg kan binomialfordelingsfunksjonen skrives som en ufullstendig betafunksjon. Dette er imidlertid allerede en mer kompleks definisjon, som bare brukes ved løsning av komplekse statistiske problemer.
Binomialfordelingen, eksempler som vi undersøkte ovenfor, er en av de mest enkle arter fordelinger i sannsynlighetsteori. Det er også en normalfordeling, som er en type binomialfordeling. Det er den mest brukte, og den enkleste å beregne. Det er også en Bernoulli-distribusjon, en Poisson-distribusjon, en betinget distribusjon. Alle karakteriserer grafisk sannsynlighetsområdene for en bestemt prosess under forskjellige forhold.
I neste avsnitt vil vi vurdere aspekter knyttet til anvendelsen av dette matematiske apparatet i det virkelige liv. Ved første øyekast ser det selvfølgelig ut til at dette er en annen matematisk ting, som som vanlig ikke finner anvendelse i det virkelige liv, og som generelt ikke er nødvendig av noen unntatt matematikere selv. Dette er imidlertid ikke tilfelle. Tross alt ble alle typer distribusjoner og deres grafiske representasjoner laget utelukkende for praktiske formål, og ikke som et innfall av forskere.

applikasjon
Den desidert viktigste anvendelsen av distribusjoner er i statistikk, hvor det kreves kompleks analyse av en mengde data. Som praksis viser, har svært mange datamatriser omtrent de samme verdifordelingene: de kritiske områdene med svært lave og svært høye verdier inneholder som regel færre elementer enn gjennomsnittsverdiene.
Analyse av store datamatriser kreves ikke bare i statistikk. Det er uunnværlig, for eksempel i fysisk kjemi. I denne vitenskapen brukes den til å bestemme mange mengder som er assosiert med tilfeldige vibrasjoner og bevegelser av atomer og molekyler.
I neste avsnitt skal vi forstå hvor viktig det er å anvende statistiske begreper som binomial fordeling av en tilfeldig variabel i hverdagen for deg og meg.

Hvorfor trenger jeg det?
Mange stiller seg dette spørsmålet når det kommer til matematikk. Og forresten, matematikk kalles ikke forgjeves vitenskapens dronning. Det er grunnlaget for fysikk, kjemi, biologi, økonomi, og i hver av disse vitenskapene brukes også en slags fordeling: om det er en diskret binomialfordeling eller en normal, spiller det ingen rolle. Og hvis vi ser nærmere på verden rundt oss, vil vi se at matematikk brukes overalt: i hverdagen, på jobben, og til og med menneskelige relasjoner kan presenteres i form av statistiske data og analyseres (dette forresten , gjøres av de som jobber i spesielle organisasjoner som er involvert i innsamling av informasjon).
La oss nå snakke litt om hva du skal gjøre hvis du trenger å vite mye mer om dette emnet enn det vi har skissert i denne artikkelen.
Informasjonen vi har gitt i denne artikkelen er langt fra fullstendig. Det er mange nyanser når det gjelder hvilken form distribusjonen kan ha. Binomialfordelingen, som vi allerede har funnet ut, er en av hovedtypene som helheten mattestatistikk og sannsynlighetsteori.
Hvis du blir interessert, eller i forbindelse med arbeidet ditt, trenger du å vite mye mer om dette emnet, du må studere den spesialiserte litteraturen. Start med et universitetskurs matematisk analyse og kom dit til delen av sannsynlighetsteori. Også kunnskap innen serier vil være nyttig, fordi den binomiale sannsynlighetsfordelingen ikke er noe mer enn en rekke påfølgende ledd.
Konklusjon
Før vi avslutter artikkelen, vil vi gjerne fortelle deg en interessant ting til. Det gjelder direkte emnet for artikkelen vår og all matematikk generelt.
Mange sier at matematikk er en ubrukelig vitenskap, og ingenting de lærte på skolen var nyttig for dem. Men kunnskap er aldri overflødig, og hvis noe ikke er nyttig for deg i livet, betyr det at du rett og slett ikke husker det. Hvis du har kunnskap kan de hjelpe deg, men hvis du ikke har det, så kan du ikke forvente hjelp fra dem.
Så vi undersøkte konseptet med binomialfordelingen og alle definisjonene knyttet til det og snakket om hvordan det brukes i livene våre.
